
合 MySQL体系结构
MySQL Server体系结构
MySQL由数据库和数据库实例组成,是单进程多线程架构(Oracle和PG都是多进程架构)。
数据库:物理操作系统文件或者其它文件的集合,在mysql中,数据库文件可以是frm、myd、myi、ibd等结尾的文件,当使用ndb存储引擎时候,不是os文件,是存放于内存中的文件。
数据库实例:由数据库后台进程/线程以及一个共享内存区组成,共享内存可以被运行的后台进程/线程所共享。
1 2 3 4 5 | top -Hp pid 可以查看某个进程的线程信息 ps -Lf pid 也可以查看某个进程的线程信息 # 线程和连接id之间的关系 select a.THREAD_OS_ID,PROCESSLIST from performance_schema.threads a; |




https://www.mysql.com/common/images/PSEA_diagram.jpg
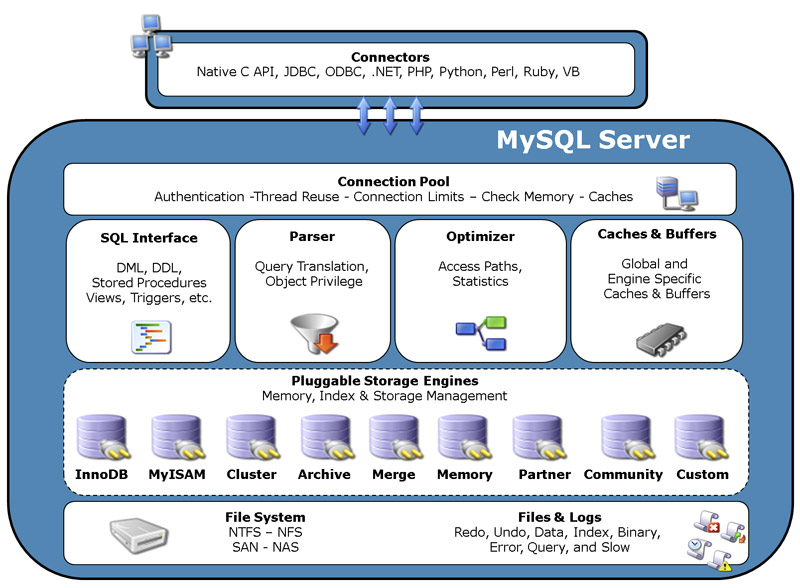
•Connectors(连接者):指的是不同语言中与SQL的交互,从图3-1中可以看到目前流行的语言都支持MySQL客户端连接。
•Connection Pool(连接池):管理缓冲用户连接、线程处理等需要缓存的需求。在这里也会进行用户账号、密码和库表权限验证。
•SQL Interface(SQL接口):接收用户执行的SQL语句,并返回查询的结果。
•Parser(查询解析器):SQL语句被传递到解析器时会进行验证和解析(解析成MySQL认识的语法,查询什么表、什么字段)。解析器是由Lex和YACC实现的,是一个很长的脚本。其主要功能是将SQL语句分解成数据结构,并将这个结构传递到后续步骤中,后续SQL语句的传递和处理就是基于这个结构的。如果在分解构成中遇到错误,则说明该SQL语句可能有语法错误或者不合理。
•Optimizer(查询优化器):在查询之前,SQL语句会使用查询优化器对查询进行优化(生成查询路径树,并选举一条最优的查询路径)。它使用“选取—投影—连接”策略进行查询。
•Caches&Buffers(缓存&缓冲):主要包含QC以及表缓存、权限缓存等。对于QC,以往主要用于MyISAM存储引擎,目前在MySQL 8.0中已放弃,对于现在非常流行的InnoDB存储引擎来讲,QC已无任何意义,因为InnoDB存储引擎有自己的且非常完善的缓存功能。除QC之外(记录缓存、key缓存,可使用参数单独关闭),该缓存机制还包括表缓存和权限缓存等,这些是属于Server层的功能,其他存储引擎仍需要使用。
•Pluggable Storage Engines(插件式存储引擎):存储引擎是MySQL中具体的与文件打交道的子系统,也是MySQL最具特色的一个地方。MySQL的存储引擎是插件式的,它根据MySQL AB公司提供的文件访问层的一个抽象接口来定制一种文件访问机制(这种访问机制就叫存储引擎)。目前存储引擎众多,且它们的优势各不相同,现在最常用于OLTP场景的是InnoDB(当然也支持OLAP存储引擎,但MySQL自身的机制并不擅长OLAP场景)。
•Files&Logs(磁盘物理文件):包含MySQL的各个引擎的数据、索引的文件,以及redo log、undo log、binary log、error log、query log、slow log等各种日志文件。
•File System(文件系统):对存储设备的空间进行组织和分配,负责文件存储并对存入的文件进行保护和检索的系统。它负责为用户建立文件,存入、读出、修改、转储文件,控制文件的存取。常见的文件系统包括XFS、NTFS、EXT4、EXT3、NFS等,通常数据库服务器使用的磁盘建议用XFS。
那么,上述各个组件之间是如何协同工作的?下面我们举一个查询例子进行说明。
假如在MySQL中有一个查询会话请求,那么大概流程如下:
(1)MySQL客户端对MySQL Server的监听端口发起请求。
(2)在连接者组件层创建连接、分配线程,并验证用户名、密码和库表权限。
(3)如果打开了query_cache,则检查之,有数据直接返回,没有继续往下执行。
(4)SQL接口组件接收SQL语句,将SQL语句分解成数据结构,并将这个结构传递到后续步骤中(将SQL语句解析成MySQL认识的语法)。
(5)查询优化器组件生成查询路径树,并选举一条最优的查询路径。
(6)调用存储引擎接口,打开表,执行查询,检查存储引擎缓存中是否有对应的缓存记录,如果没有就继续往下执行。
(7)到磁盘物理文件中寻找数据。
(8)当查询到所需要的数据之后,先写入存储引擎缓存中,如果打开了query_cache,也会同时写进去。
(9)返回数据给客户端。
(10)关闭表。
(11)关闭线程。
(12)关闭连接。

MySQL 使用典型的客户端/服务器(Client/Server)结构,结构图如下所示:

查询缓存,用于将执行过的SELECT语句和结果缓存在内存中。每次执行查询之前判断是否命中缓存,如果命中直接返回缓存的结果。缓存命中需要满足许多条件,SQL语句完全相同,上下文环境相同等。实际上除非是只读应用,查询缓存的失效频率非常高,任何对表的修改都会导致缓存失效;因此,查询缓存在MySQL 8.0中已经被删除。
SQL接口,接收客户端发送的各种DML和DDL命令,并且返回用户查询的结果。另外还包括所有的内置函数(日期、时间、数学以及加密函数)和跨存储引擎的功能,例如存储过程、触发器、视图等。
解析器,对SQL语句进行解析,例如语义和语法的分析和检查,以及对象访问权限检查等。
优化器,利用数据库的统计信息决定SQL语句的最佳执行方式。使用索引还是全表扫描的方式访问单个表,多表连接的实现方式等。优化器是决定查询性能的关键组件,而数据库的统计信息是优化器判断的基础。
缓存与缓冲,由一系列缓存组成的,例如数据缓存、索引缓存以及对象权限缓存等。对于已经访问过的磁盘数据,在缓冲区中进行缓存;下次访问时可以直接读取内存中的数据,从而减少磁盘IO。
存储引擎,存储引擎是对底层物理数据执行实际操作的组件,为服务器层提供各种操作数据的API。MySQL支持插件式的存储引擎,包括InnoDB、MyISAM、Memory等。
InnoDB存储引擎体系结构
InnoDB存储引擎体系结构如图所示(该图来自Percona Database Performance Blog,参考链接:https://www.percona.com/blog/2010/04/26/xtradb-innodb-internals-in-drawing/)。
https://myslide.cn/slides/21572#





{kind=link}