
合 将US7ASCII字符集的dmp文件导入到ZHS16GBK字符集的数据库中
Tags: Oracle乱码expimpUS7ASCIIZHS16GBK
文章目录[隐藏]
【exp/imp】将US7ASCII字符集的dmp文件导入到ZHS16GBK字符集的数据库中
前言部分
导读和注意事项
各位技术爱好者,看完本文后,你可以掌握如下的技能,也可以学到一些其它你所不知道的知识,\~O(∩_∩)O\~:
① 如何将US7ASCII字符集的dmp文件导入到ZHS16GBK字符集的数据库中(重点,2种方法)?
② 从dmp文件可以获取到哪些信息?如何从dmp文件获取到dmp文件的字符集(重点,N种方法)?
③ 如何从dmp文件中获取到其中的DDL语句,例如建表、建索引语句等(2种方法)
④ dmp文件导入的一般步骤
⑤ imp工具的indexfile选项的作用
⑥ 软件UE、EditPlus、Pilotedit软件的使用
本文相关知识点
可以从dmp文件获取哪些信息?
在开发中常常碰到,需要导入dmp文件到现有数据库。这里的dmp文件可能来自于其它系统,所以,一般情况下是不知道导出程序(exp)的版本、导出时间或者导出模式等信息的。那么如何从现有的dmp文件中获取到这些信息呢?下面作者将一一讲解。
获取基本信息:导出的版本、时间、导出的用户
下面的示例中exp_ddl_lhr_02.dmp是生成的dmp文件:
1 2 3 4 5 6 7 8 9 10 11 12 | [ZFZHLHRDB1:oracle]:/tmp>strings exp_ddl_lhr_02.dmp | head -10 TEXPORT:V11.02.00 ====》版本号 DSYS ====》使用SYS用户导出 RTABLES ====》基于表模式导出,RUSERS表示基于用户模式,RENTIRE表示基于全库模式 4096 Tue Aug 2 16:8:8 2016/tmp/exp_ddl_lhr_02.dmp====》生成的时间和文件地址 #C#G #C#G +00:00 BYTE UNUSED |
获取dmp文件中的表信息
下面的示例中,exp_ddl_lhr_02.dmp是生成的dmp文件:
1 2 | [ZFZHLHRDB1:oracle]:/tmp>strings exp_ddl_lhr_02.dmp | grep "CREATE TABLE"|awk '{print $3}'|sed 's/"//g' EMP ====》说明exp_ddl_lhr_02.dmp中只有一个emp表 |
解析dmp文件生成parfile文件
下面的示例中,exp_ddl_lhr_03.dmp是生成的dmp文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | [ZFZHLHRDB1:oracle]:/tmp>strings exp_ddl_lhr_03.dmp | grep "CREATE TABLE"|awk '{print $3}'|sed 's/"//g'|awk '{ if (FNR==1) print "tables="$1 ; else print ","$1 }' tables=DEF$_AQCALL ,DEF$_AQERROR ,DEF$_CALLDEST ,DEF$_DEFAULTDEST ,DEF$_DESTINATION ,DEF$_ERROR ,DEF$_LOB ,DEF$_ORIGIN ,DEF$_PROPAGATOR ,DEF$_PUSHED_TRANSACTIONS ,MVIEW$_ADV_INDEX [ZFZHLHRDB1:oracle]:/tmp> |
如何查看dmp文件的字符集
imp导入命令查看
有2种办法可以查看dmp文件的字符集,第一种办法为imp导入命令查看,示例如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | [ZFLHRZHDB1:oracle]:/oracle>ORACLE_SID=lhrdb [ZFLHRZHDB1:oracle]:/oracle>export NLS_LANG=AMERICAN_AMERICA.AL32UTF8 [ZFLHRZHDB1:oracle]:/oracle>exp \'/ AS SYSDBA\' tables=scott.emp file=/tmp/exp_ddl_lhr_03.dmp log=/tmp/exp_table.log buffer=41943040 rows=n compress=n Export: Release 11.2.0.4.0 - Production on Tue Oct 25 17:14:49 2016 Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved. Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production With the Partitioning, Real Application Clusters, Automatic Storage Management, OLAP, Data Mining and Real Application Tes Export done in AL32UTF8 character set and AL16UTF16 NCHAR character set<<<--当前的NLS_LANG环境变量的值,即生成的dmp文件的字符集 server uses ZHS16GBK character set (possible charset conversion)<<<<<<<--当前数据库的字符集 Note: table data (rows) will not be exported About to export specified tables via Conventional Path ... Current user changed to SCOTT . . exporting table EMP EXP-00091: Exporting questionable statistics. EXP-00091: Exporting questionable statistics. Export terminated successfully with warnings. [ZFLHRZHDB1:oracle]:/oracle>ORACLE_SID=mydb <<---更换数据库 [ZFLHRZHDB1:oracle]:/oracle>export NLS_LANG=AMERICAN_AMERICA.ZHS16GBK [ZFLHRZHDB1:oracle]:/oracle>imp \'/ AS SYSDBA\' tables=xxx.xx file=/tmp/exp_ddl_lhr_03.dmp Import: Release 11.2.0.4.0 - Production on Tue Oct 25 16:27:15 2016 Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved. Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production With the Partitioning, Real Application Clusters, Automatic Storage Management, OLAP, Data Mining and Real Application Tes Export file created by EXPORT:V11.02.00 via conventional path<<<<<<<<<----dmp文件的导出版本号 import done in ZHS16GBK character set and AL16UTF16 NCHAR character set<<<<<<--当前的NLS_LANG环境变量的值 import server uses WE8ISO8859P1 character set (possible charset conversion)<<<<<<---当前数据库的字符集 export client uses AL32UTF8 character set (possible charset conversion)<<<<<<--dmp文件的字符集 IMP-00029: cannot qualify table name by owner (xxx.xx), use FROMUSER parameter IMP-00000: Import terminated unsuccessfully |
如果NLS_LANG的值和当前数据库的字符集相同,那么将不显示“server uses”和“import server uses”行。如果没有显示“export client”行,那么说明当前dmp文件的字符集和当前的NLS_LANG环境变量的值相同。无论是使用exp还是imp工具都会显示当前的NLS_LANG环境变量的值(表现为“Export done”、“import done”)。
十六进制的第2和第3个字节
第二种查看dmp文件字符集的办法是,以十六进制的方式打开dmp文件,然后查看第2和第3个字节。如下所示:
1 2 3 4 5 6 | [ZFLHRZHDB1:oracle]:/oracle>cat /tmp/exp_ddl_lhr_03.dmp |od -x|head -1|awk '{print $2 $3}'|cut -c 1-2,7-8 0369 [ZFLHRZHDB1:oracle]:/oracle>cat /tmp/exp_ddl_lhr_03.dmp |od -x|head -1 0000000 0303 4569 5058 524f 3a54 3156 2e30 3230 [oracle@rhel6lhr env_oracle]$ |

然后在数据库中可以查到十六进制0369代表的字符集:
1 2 3 4 5 | SYS@lhrdb> SELECT NLS_CHARSET_NAME(TO_NUMBER('0369','XXXX')) FROM DUAL; NLS_CHARSET_NAME(TO_NUMBER('0369','XXXX' ---------------------------------------- AL32UTF8 |
以上结果说明dmp文件的字符集是UTF8。若dmp文件在Windows平台下,则可以使用软件UltraEdit(UE)、EditPlus或Pilotedit等文本编辑工具以十六进制的方式打开dmp文件查看。其中,软件Pilotedit可以轻松打开上G的文件。示例如下:
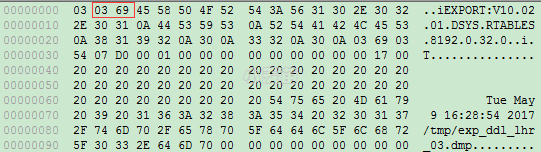
需要注意的是,十六进制在Linux和Windows下顺序不同。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | SELECT NLS_CHARSET_NAME(TO_NUMBER('0001', 'XXXX')) US7ASCII, NLS_CHARSET_NAME(TO_NUMBER('0354', 'XXXX')) ZHS16GBK, NLS_CHARSET_NAME(TO_NUMBER('0369', 'XXXX')) AL32UTF8, TO_CHAR(NLS_CHARSET_ID('US7ASCII'), 'XXXX') US7ASCII_ID, TO_CHAR(NLS_CHARSET_ID('ZHS16GBK'), 'XXXX') ZHS16GBK_ID, TO_CHAR(NLS_CHARSET_ID('AL32UTF8'), 'XXXX') AL32UTF8_ID FROM DUAL; SYS@ora10g> SELECT NLS_CHARSET_NAME(TO_NUMBER('0001', 'XXXX')) US7ASCII, 2 NLS_CHARSET_NAME(TO_NUMBER('0354', 'XXXX')) ZHS16GBK, 3 NLS_CHARSET_NAME(TO_NUMBER('0369', 'XXXX')) AL32UTF8, 4 TO_CHAR(NLS_CHARSET_ID('US7ASCII'), 'XXXX') , 5 TO_CHAR(NLS_CHARSET_ID('ZHS16GBK'), 'XXXX') , 6 TO_CHAR(NLS_CHARSET_ID('AL32UTF8'), 'XXXX') 7 FROM DUAL; US7ASCII ZHS16GBK AL32UTF8 TO_CH TO_CH TO_CH ---------------------------------------- ---------------------------------------- ---------------------------------------- ----- ----- ----- US7ASCII ZHS16GBK AL32UTF8 1 354 369 SYS@ora10g> |

如何获取数据库DDL的创建语句
数据泵工具(impdp)工具给我们提供了SQLFILE的命令行选项,只获取DDL语句,并未真正的执行数据导入。另外,若单纯为了导出DDL语句则可以在使用expdp导出的时候使用CONTENT=METADATA_ONLY和EXCLUDE=STATISTICS选项,这样导出的DMP文件比较小。如下所示:
1 2 3 4 | expdp \'/ AS SYSDBA\' DIRECTORY=DATA_PUMP_DIR DUMPFILE=lhrsql20161215.dmp LOGFILE=lhrsql20161215.log CONTENT=METADATA_ONLY SCHEMAS=SCOTT EXCLUDE=STATISTICS impdp \'/ AS SYSDBA\' DIRECTORY=DATA_PUMP_DIR DUMPFILE=lhrsql20161215.dmp LOGFILE=imp_exptest.log SQLFILE=expddl_lhr.sql |
查看expddl_lhr.sql文件即可获取DDL语句。
imp工具使用SHOW=Y LOG=GET_DDL.sql的方式,可以看到清晰的DDL脚本,同时也不会真正的执行数据导入。另外,若单纯为了导出DDL语句则可以在使用exp导出的时候使用ROWS=N选项,这样导出的DMP文件比较小。如下所示:
1 2 3 | exp \'/ AS SYSDBA\' TABLES=SCOTT.EMP FILE=/tmp/exp_ddl_lhr_01.dmp LOG=/tmp/exp_table.log BUFFER=41943040 ROWS=N COMPRESS=N imp \'/ AS SYSDBA\' FILE=/tmp/exp_ddl_lhr_01.dmp SHOW=Y LOG=/tmp/get_ddl.sql BUFFER=20480000 FULL=Y |
查看get_ddl.sql文件即可获取DDL语句。
1 2 3 4 5 6 7 8 | ---- 生成DDL语句不会导入数据 --expdp \'/ AS SYSDBA\' tables=lhr.exptest directory=DATA_PUMP_DIR dumpfile=exptest.dmp logfile=exp_exptest.dmp EXCLUDE=STATISTICS --expdp \'/ AS SYSDBA\' directory=DATA_PUMP_DIR dumpfile=lhrsql20161215.dmp logfile=lhrsql20161215.log content=metadata_only schemas=SCOTT EXCLUDE=STATISTICS impdp \'/ AS SYSDBA\' directory=DATA_PUMP_DIR dumpfile=lhrsql20161215.dmp logfile=imp_exptest.log sqlfile=exptest.sql exp \'/ AS SYSDBA\' tables=scott.emp file=/tmp/exp_ddl_lhr_01.dmp log=/tmp/exp_table.log buffer=41943040 rows=n compress=n imp \'/ AS SYSDBA\' file=/tmp/exp_ddl_lhr_01.dmp show=y log=/tmp/get_ddl.sql buffer=20480000 full=y |
imp示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | [ZFZHLHRDB1:oracle]:/oracle>exp \'/ AS SYSDBA\' tables=scott.emp file=/tmp/exp_ddl_lhr_01.dmp log=/tmp/exp_table.log buffer=41943040 rows=n compress=n Export: Release 11.2.0.4.0 - Production on Tue Aug 2 15:42:11 2016 Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved. Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production With the Partitioning, Real Application Clusters, Automatic Storage Management, OLAP, Data Mining and Real Application Tes Export done in ZHS16GBK character set and AL16UTF16 NCHAR character set Note: table data (rows) will not be exported About to export specified tables via Conventional Path ... Current user changed to SCOTT . . exporting table EMP Export terminated successfully without warnings. [ZFZHLHRDB1:oracle]:/oracle>imp \'/ AS SYSDBA\' file=/tmp/exp_ddl_lhr_01.dmp show=y log=/tmp/get_ddl.sql buffer=20480000 full=y Import: Release 11.2.0.4.0 - Production on Tue Aug 2 15:42:44 2016 Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved. Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production With the Partitioning, Real Application Clusters, Automatic Storage Management, OLAP, Data Mining and Real Application Tes Export file created by EXPORT:V11.02.00 via conventional path import done in ZHS16GBK character set and AL16UTF16 NCHAR character set . importing SYS's objects into SYS . importing SCOTT's objects into SCOTT "ALTER SESSION SET CURRENT_SCHEMA= "SCOTT"" "CREATE TABLE "EMP" ("EMPNO" NUMBER(4, 0), "ENAME" VARCHAR2(10), "JOB" VARCH" "AR2(9), "MGR" NUMBER(4, 0), "HIREDATE" DATE, "SAL" NUMBER(7, 2), "COMM" NUM" "BER(7, 2), "DEPTNO" NUMBER(2, 0)) PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRAN" "S 255 STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 FREELISTS 1 FREELIST " "GROUPS 1 BUFFER_POOL DEFAULT) TABLESPACE "USERS" LOGGING NOCOMPRESS" "CREATE UNIQUE INDEX "PK_EMP" ON "EMP" ("EMPNO" ) PCTFREE 10 INITRANS 2 MAX" "TRANS 255 STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 FREELISTS 1 FREEL" "IST GROUPS 1 BUFFER_POOL DEFAULT) TABLESPACE "USERS" LOGGING" "ALTER SESSION SET CURRENT_SCHEMA= "SCOTT"" "ALTER TABLE "EMP" ADD CONSTRAINT "PK_EMP" PRIMARY KEY ("EMPNO") USING INDE" "X PCTFREE 10 INITRANS 2 MAXTRANS 255 STORAGE(INITIAL 65536 NEXT 1048576 MIN" "EXTENTS 1 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT) TABLESPACE "US" "ERS" LOGGING ENABLE " "ALTER TABLE "EMP" ADD CONSTRAINT "FK_DEPTNO" FOREIGN KEY ("DEPTNO") REFEREN" "CES "DEPT" ("DEPTNO") ENABLE NOVALIDATE" "ALTER TABLE "EMP" ENABLE CONSTRAINT "FK_DEPTNO"" Import terminated successfully without warnings. [ZFZHLHRDB1:oracle]:/oracle> |
由于格式比较混乱,直接运行会报错,建荣的书中给了一段代码来格式化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 | [ZFZHLHRDB1:oracle]:/tmp>more /tmp/get_ddl.sql Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production With the Partitioning, Real Application Clusters, Automatic Storage Management, OLAP, Data Mining and Real Application Tes Export file created by EXPORT:V11.02.00 via conventional path import done in ZHS16GBK character set and AL16UTF16 NCHAR character set . importing SYS's objects into SYS . importing SCOTT's objects into SCOTT "ALTER SESSION SET CURRENT_SCHEMA= "SCOTT"" "CREATE TABLE "EMP" ("EMPNO" NUMBER(4, 0), "ENAME" VARCHAR2(10), "JOB" VARCH" "AR2(9), "MGR" NUMBER(4, 0), "HIREDATE" DATE, "SAL" NUMBER(7, 2), "COMM" NUM" "BER(7, 2), "DEPTNO" NUMBER(2, 0)) PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRAN" "S 255 STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 FREELISTS 1 FREELIST " "GROUPS 1 BUFFER_POOL DEFAULT) TABLESPACE "USERS" LOGGING NOCOMPRESS" "CREATE UNIQUE INDEX "PK_EMP" ON "EMP" ("EMPNO" ) PCTFREE 10 INITRANS 2 MAX" "TRANS 255 STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 FREELISTS 1 FREEL" "IST GROUPS 1 BUFFER_POOL DEFAULT) TABLESPACE "USERS" LOGGING" "ALTER SESSION SET CURRENT_SCHEMA= "SCOTT"" "ALTER TABLE "EMP" ADD CONSTRAINT "PK_EMP" PRIMARY KEY ("EMPNO") USING INDE" "X PCTFREE 10 INITRANS 2 MAXTRANS 255 STORAGE(INITIAL 65536 NEXT 1048576 MIN" "EXTENTS 1 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT) TABLESPACE "US" "ERS" LOGGING ENABLE " "ALTER TABLE "EMP" ADD CONSTRAINT "FK_DEPTNO" FOREIGN KEY ("DEPTNO") REFEREN" "CES "DEPT" ("DEPTNO") ENABLE NOVALIDATE" "ALTER TABLE "EMP" ENABLE CONSTRAINT "FK_DEPTNO"" Import terminated successfully without warnings. [ZFZHLHRDB1:oracle]:/tmp>more /tmp/gettabddl.sh awk ' / \"BEGIN / { N=1; } / \"CREATE / { N=1; } / \"CREATE INDEX/ { N=1; } / \"CREATE UNIQUE INDEX/ { N=1; } / \"ALTER / { N=1; } / \" ALTER / { N=1; } / \"ANALYZE / { N=1; } / \"GRANT / { N=1; } / \"COMMENT / { N=1; } / \"AUDIT / { N=1; } N==1 { printf "\n/\n"; N++ } /\"$/ { if (N==0) next; s=index( $0, "\"" ); ln0=length( $0 ) if ( s!=0 ) { lcnt++ if ( lcnt >= 30 ) { ln=substr( $0,s+1,length( substr($0,s+1))-1) t=index( ln, ")," ) if ( t==0 ) { t=index( ln, ", " ) } if ( t==0 ) { t=index( ln, ") " ) } if ( t > 0 ) { printf "%s\n%s",substr( ln,1,t+1), substr(ln, t+2) lcnt=0 } else { printf "%s", ln if ( ln0 < 78 ) { printf "\n" ; lcnt=0 } } } else { printf "%s",substr( $0,s+1,length( substr($0,s+1))-1 ) if ( ln0 < 78 ) { printf "\n" ; lcnt=0 } } } } END { printf "\n/\n"} ' $* |sed '1,2d; /^$/ d; s/STORAGE *(INI/~ STORAGE (INI/g; s/, "/,~ "/g; s/ (\"/~ &/g; s/PCT[FI]/~ &/g; s/[( ]PARTITION /~&/g; s/) TABLESPACE/)~ TABLESPACE/g; s/ , / ,~/g; s/ DATAFILE /&~/' | tr "~" "\n" [ZFZHLHRDB1:oracle]:/tmp> [ZFZHLHRDB1:oracle]:/tmp>ksh /tmp/gettabddl.sh /tmp/get_ddl.sql > /tmp/gen_tabddl.sql [ZFZHLHRDB1:oracle]:/tmp>more /tmp/gen_tabddl.sql ALTER SESSION SET CURRENT_SCHEMA= "SCOTT" / CREATE TABLE "EMP" ("EMPNO" NUMBER(4, 0), "ENAME" VARCHAR2(10), "JOB" VARCHAR2(9), "MGR" NUMBER(4, 0), "HIREDATE" DATE, "SAL" NUMBER(7, 2), "COMM" NUMBER(7, 2), "DEPTNO" NUMBER(2, 0)) PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 STORAGE (INITIAL 65536 NEXT 1048576 MINEXTENTS 1 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT) TABLESPACE "USERS" LOGGING NOCOMPRESS / CREATE UNIQUE INDEX "PK_EMP" ON "EMP" ("EMPNO" ) PCTFREE 10 INITRANS 2 MAXTRANS 255 STORAGE (INITIAL 65536 NEXT 1048576 MINEXTENTS 1 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT) TABLESPACE "USERS" LOGGING / ALTER SESSION SET CURRENT_SCHEMA= "SCOTT" / ALTER TABLE "EMP" ADD CONSTRAINT "PK_EMP" PRIMARY KEY ("EMPNO") USING INDEX PCTFREE 10 INITRANS 2 MAXTRANS 255 STORAGE (INITIAL 65536 NEXT 1048576 MINEXTENTS 1 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT) TABLESPACE "USERS" LOGGING ENABLE / ALTER TABLE "EMP" ADD CONSTRAINT "FK_DEPTNO" FOREIGN KEY ("DEPTNO") REFERENCES "DEPT" ("DEPTNO") ENABLE NOVALIDATE / ALTER TABLE "EMP" ENABLE CONSTRAINT "FK_DEPTNO" / [ZFZHLHRDB1:oracle]:/tmp> |
