合 DG环境主库丢失归档情况下数据文件的恢复
【故障处理】DG环境主库丢失归档情况下数据文件的恢复
前言部分
导读和注意事项
各位技术爱好者,看完本文后,你可以掌握如下的技能,也可以学到一些其它你所不知道的知识,\~O(∩_∩)O\~:
① BBED的编译
② BBED修改文件头让其跳过归档从而可以ONLINE(重点)
③ OS命名格式转换为ASM的命名格式
④ DG环境中备库丢失数据文件的情况下的处理过程(重点)
⑤ 数据文件OFFLINE后应立即做一次RECOVER操作
⑥ BBED环境中kscnwrp的使用
⑦ 查询表空间的大小,表空间大小为空,数据文件大小为空的情况
故障分析及解决过程
故障环境介绍
| 项目 | 源库 | DG库 |
|---|---|---|
| db 类型 | RAC | RAC |
| db version | 11.2.0.3.7 | 11.2.0.3.7 |
| db 存储 | ASM | ASM |
| OS版本及kernel版本 | AIX 64位 7.1.0.0 | AIX 64位 7.1.0.0 |
| 关系 | 主备库为RAC+RAC的物理DG环境 |
故障发生现象及报错信息
今天查询一套DG环境的表空间大小的时候,发现一个表空间的返回值为空,很奇怪,起初我以为是自己的脚本问题,可是这个脚本是自己写的,而且用了很长时间的了,还花了几分钟的时间又仔细审核了一下脚本,没发现有什么不对的地方。
查询表空间大小的脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 | set pagesize 9999 line 9999 col TS_Name format a30 WITH WT1 AS (SELECT TS.TABLESPACE_NAME, DF.ALL_BYTES, DECODE(DF.TYPE, 'D', NVL(FS.FREESIZ, 0), 'T', DF.ALL_BYTES - NVL(FS.FREESIZ, 0)) FREESIZ, DF.MAXSIZ, TS.BLOCK_SIZE, TS.LOGGING, TS.FORCE_LOGGING, TS.CONTENTS, TS.EXTENT_MANAGEMENT, TS.SEGMENT_SPACE_MANAGEMENT, TS.RETENTION, TS.DEF_TAB_COMPRESSION, DF.TS_DF_COUNT, TS.BIGFILE, TS.STATUS FROM DBA_TABLESPACES TS, (SELECT 'D' TYPE, TABLESPACE_NAME, COUNT(*) TS_DF_COUNT, SUM(BYTES) ALL_BYTES, SUM(DECODE(MAXBYTES, 0, BYTES, MAXBYTES)) MAXSIZ FROM DBA_DATA_FILES D GROUP BY TABLESPACE_NAME UNION ALL SELECT 'T', TABLESPACE_NAME, COUNT(*) TS_DF_COUNT, SUM(BYTES) ALL_BYTES, SUM(DECODE(MAXBYTES, 0, BYTES, MAXBYTES)) FROM DBA_TEMP_FILES D GROUP BY TABLESPACE_NAME) DF, (SELECT TABLESPACE_NAME, SUM(BYTES) FREESIZ FROM DBA_FREE_SPACE GROUP BY TABLESPACE_NAME UNION ALL SELECT TABLESPACE_NAME, SUM(D.BLOCK_SIZE * A.BLOCKS) BYTES FROM GV$SORT_USAGE A, DBA_TABLESPACES D WHERE A.TABLESPACE = D.TABLESPACE_NAME GROUP BY TABLESPACE_NAME) FS WHERE TS.TABLESPACE_NAME = DF.TABLESPACE_NAME AND TS.TABLESPACE_NAME = FS.TABLESPACE_NAME(+)) SELECT (SELECT A.TS# FROM V$TABLESPACE A WHERE A.NAME = UPPER(T.TABLESPACE_NAME)) TS#, T.TABLESPACE_NAME TS_NAME, ROUND(T.ALL_BYTES / 1024 / 1024) TS_SIZE_M, ROUND(T.FREESIZ / 1024 / 1024) FREE_SIZE_M, ROUND((T.ALL_BYTES - T.FREESIZ) / 1024 / 1024) USED_SIZE_M, ROUND((T.ALL_BYTES - T.FREESIZ) * 100 / T.ALL_BYTES, 3) USED_PER, ROUND(MAXSIZ / 1024 / 1024 / 1024, 3) MAX_SIZE_G, ROUND(DECODE(MAXSIZ, 0, TO_NUMBER(NULL), (T.ALL_BYTES - FREESIZ)) * 100 / MAXSIZ, 3) USED_PER_MAX, ROUND(T.BLOCK_SIZE) BLOCK_SIZE, T.LOGGING, T.BIGFILE, T.STATUS, T.TS_DF_COUNT FROM WT1 T UNION ALL SELECT TO_NUMBER('') TS#, 'ALL TS:' TS_NAME, ROUND(SUM(T.ALL_BYTES) / 1024 / 1024, 3) TS_SIZE_M, ROUND(SUM(T.FREESIZ) / 1024 / 1024) FREE_SIZE_M, ROUND(SUM(T.ALL_BYTES - T.FREESIZ) / 1024 / 1024) USED_SIZE_M, ROUND(SUM(T.ALL_BYTES - T.FREESIZ) * 100 / SUM(T.ALL_BYTES), 3) USED_PER, ROUND(SUM(MAXSIZ) / 1024 / 1024 / 1024) MAX_SIZE, TO_NUMBER('') "USED,% of MAX Size", TO_NUMBER('') BLOCK_SIZE, '' LOGGING, MAX(T.BIGFILE), MAX(T.STATUS), TO_NUMBER('') TS_DF_COUNT FROM WT1 T ORDER BY TS#; |
结果如下图:
因为表空间是ONLINE的,若是OFFLINE的话,结果自然为空,由于只有一个数据文件,那就看看数据文件的状态:
SELECT * FROM v\$datafile d WHERE d.FILE#=64;
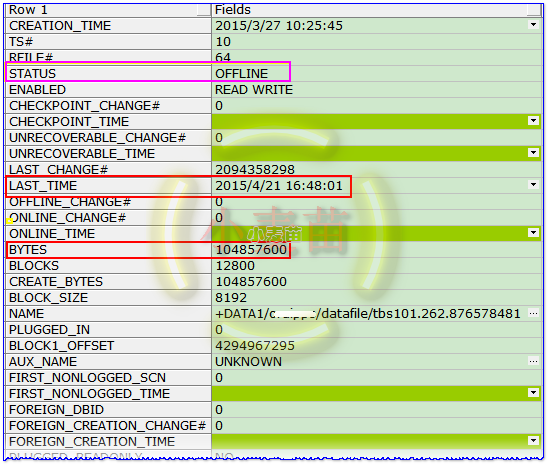
果然数据文件是64,数据文件为OFFLINE状态,而且去备库查看的时候数据文件也是OFFLINE的。这里有一个LAST_TIME需要注意,日志为2015年4月21号,而现在都2016年9月21号了,看来是很久很久很久没有用这个数据文件了。好吧,很久没有写BLOG了,今天就以这个案例为主,说说其修复过程把。
健康检查报告
运行
用自己的健康检查报告看一下能否发现这个问题呢?
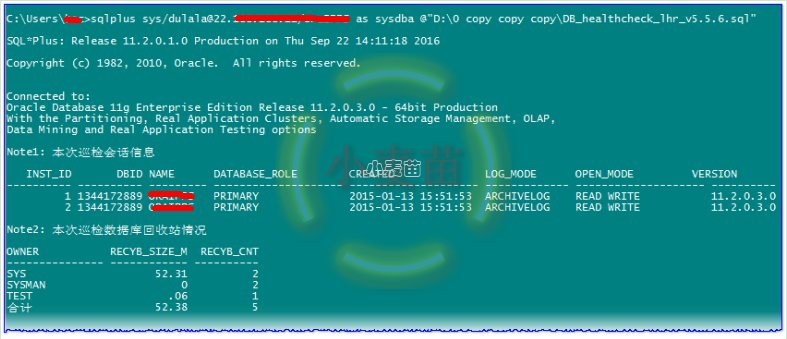
跑完之后,生成的报告在当前目录,报告的目录大概如下所示:
概况
先看看数据库的概况:
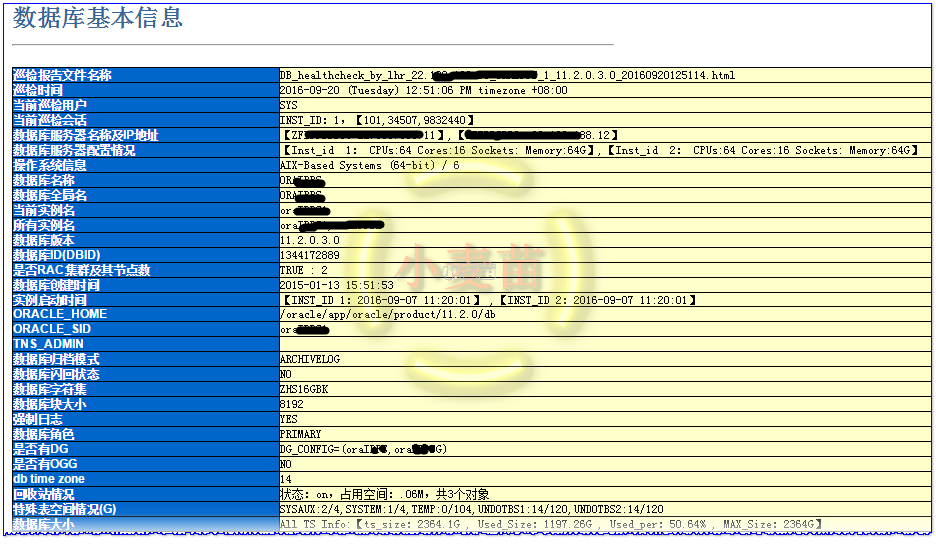
1级告警:数据文件OFFLINE
再看看,健康检查的结果:
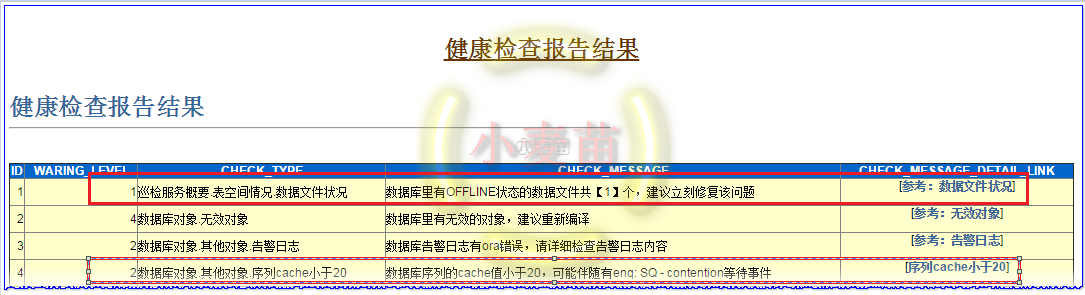
有2个地方很重要,1个数据文件有OFFLINE的,第二个是序列的CACHE值小于20,并且已经有enq: SQ - contention等待事件的发生了,说明比较严重,应该修改其cache值。我们点击到相应的位置可以查看细节。
可以看到是64号文件是OFFLINE状态的。
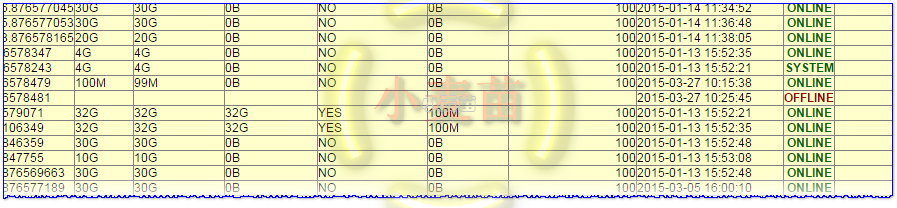
2级告警:序列问题
另外,我们看看报告中提到的序列等待问题,可以看到有6个序列的cache值设置有问题,已经导致了会话阻塞了,这部分的cache值强烈建议修改,修改语句在报告中也已经给出。

2级告警:告警日志问题
告警日志问题不是很大,可以忽略。
4级告警:无效对象

无效对象也可以修改一下,报告中提供了具体的脚本。
好了,报告不多看了,今天的主题是如何修复那个OFFLINE的数据问题,报告的脚本内容可以私聊我。
故障分析及解决过程
因为是DG环境,所以首先我们来恢复主库,然后再修复备库的文件问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | SYS@oraLHRD1> select status from v$datafile d WHERE d.FILE#=64; STATUS ------- OFFLINE SYS@oraLHRD1> select file#,online_status,change#,ERROR from v$recover_file; FILE# ONLINE_ CHANGE# ERROR ---------- ------- ---------- ----------------------------------------------------------------- 64 OFFLINE 1764555149 SYS@oraLHRD1> alter database datafile 64 online; alter database datafile 64 online * ERROR at line 1: ORA-01113: file 64 needs media recovery ORA-01110: data file 64: '+DATA1/oralhrs/datafile/tbs101.262.876578481' SYS@oraLHRD1> recover datafile 64; ORA-00279: change 1764555149 generated at 03/27/2015 10:42:00 needed for thread 2 ORA-00289: suggestion : /arch/2_1128_868895513.arc ORA-00280: change 1764555149 for thread 2 is in sequence #1128 Specify log: {<RET>=suggested | filename | AUTO | CANCEL} AUTO ORA-00308: cannot open archived log '/arch/2_1128_868895513.arc' ORA-27037: unable to obtain file status IBM AIX RISC System/6000 Error: 2: No such file or directory Additional information: 3 ORA-00308: cannot open archived log '/arch/2_1128_868895513.arc' ORA-27037: unable to obtain file status IBM AIX RISC System/6000 Error: 2: No such file or directory Additional information: 3 SYS@oraLHRD1> ! ls /arch/2_1128_868895513.arc ls: 0653-341 The file /arch/2_1128_868895513.arc does not exist. |
可以看到要恢复64号文件需要的是1128号归档日志,从之前的查询我们也知道日志最后一次访问是2015年4月21,而现在系统的归档号为1W多了:
SELECT * FROM v\$log d WHERE d.STATUS='CURRENT' ORDER BY thread#;

SELECT a.FILE#, a.NAME,a.CHECKPOINT_CHANGE#,a.LAST_CHANGE#,status FROM v\$datafile a;
SELECT a.FILE#,a.NAME,a.RECOVER,a.CHECKPOINT_CHANGE#,status FROM v\$datafile_header a;
那目前是数据文件OFFLINE,而归档文件又丢失了,如果想把该文件ONLINE,我们必须采用BBED来推进数据文件的SCN号到最近的日志号才可以。有关该部分的理论知识可以参考: 【BBED】丢失归档文件情况下的数据文件的恢复:http://blog.itpub.net/26736162/viewspace-2079337/
这里我们依然采用BBED来修复该问题。
注意:由于我们的环境是DG环境,所以先把备库的监听器停掉,以免恢复的过程中,主库生成的日志传递到备库,而主库日志被删除后,修复该文件就又得往前推进了,所以先把备库的监听停掉,确保主库的日志不被删除。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | [ZFLHRSDB4:root]:/>crsctl stat res -t -------------------------------------------------------------------------------- NAME TARGET STATE SERVER STATE_DETAILS -------------------------------------------------------------------------------- Local Resources -------------------------------------------------------------------------------- ora.LISTENER.lsnr ONLINE ONLINE zflhrsdb3 ONLINE ONLINE zflhrsdb4 ora.LISTENER_DG.lsnr====>>>>> 这个是DG的监听器 ONLINE ONLINE zflhrsdb3 ONLINE ONLINE zflhrsdb4 ora.asm ONLINE ONLINE zflhrsdb3 Started ONLINE ONLINE zflhrsdb4 Started ora.gsd OFFLINE OFFLINE zflhrsdb3 OFFLINE OFFLINE zflhrsdb4 ora.net1.network ONLINE ONLINE zflhrsdb3 ONLINE ONLINE zflhrsdb4 ora.ons ONLINE ONLINE zflhrsdb3 ONLINE ONLINE zflhrsdb4 ora.registry.acfs ONLINE ONLINE zflhrsdb3 ONLINE ONLINE zflhrsdb4 -------------------------------------------------------------------------------- Cluster Resources -------------------------------------------------------------------------------- ora.LISTENER_SCAN1.lsnr 1 ONLINE ONLINE zflhrsdb4 ora.cvu 1 ONLINE ONLINE zflhrsdb4 ora.oc4j 1 ONLINE ONLINE zflhrsdb4 ora.oralhrsg.db 1 ONLINE ONLINE zflhrsdb3 Open,Readonly 2 ONLINE ONLINE zflhrsdb4 Open,Readonly ora.scan1.vip 1 ONLINE ONLINE zflhrsdb4 ora.zflhrsdb3.vip 1 ONLINE ONLINE zflhrsdb3 ora.zflhrsdb4.vip 1 ONLINE ONLINE zflhrsdb4 [ZFLHRSDB4:root]:/> [ZFLHRSDB4:root]:/> [ZFLHRSDB4:root]:/> [ZFLHRSDB4:root]:/> [ZFLHRSDB4:root]:/>crsctl stop res ora.LISTENER_DG.lsnr CRS-2673: Attempting to stop 'ora.LISTENER_DG.lsnr' on 'zflhrsdb4' CRS-2673: Attempting to stop 'ora.LISTENER_DG.lsnr' on 'zflhrsdb3' CRS-2677: Stop of 'ora.LISTENER_DG.lsnr' on 'zflhrsdb4' succeeded CRS-2677: Stop of 'ora.LISTENER_DG.lsnr' on 'zflhrsdb3' succeeded [ZFLHRSDB4:root]:/> |
接下来就可以做恢复操作了。
修复主库的OFFLINE文件
首先,64号文件当前的SCN号1764555149,我们需要将其修改为15760391176,而日志号也需要转换为11087号,这些都需要转换为十六进制,如下:
1 2 3 4 5 6 7 8 | SYS@oraLHRD2> SELECT TO_CHAR(1764555149, 'xxxxxxxxxxxx') CUR_SCN, 2 TO_CHAR(15760391176, 'xxxxxxxxxxxx') TARGET_SCN, 3 TO_CHAR(11087, 'xxxxxxxxxxxx') TARGET_SEQ 4 FROM DUAL; CUR_SCN TARGET_SCN TARGET_SEQ ------------- ------------- ------------- 692cf98d 3ab647c08 3275 |
692cf98d和后边BBED查询出来的数据文件头的结果一致。