
合 MSSQL 2016使用查询存储来监视性能
Tags: SQL Server整理自网络整理自官网查询存储MSSQL 2016
- 简介
- 查询存储存储过程
- 目录视图
- 启用查询存储
- 使用 SQL Server Management Studio 中的“查询存储”页面
- 使用 Transact-SQL 语句
- 查询存储中的信息
- 次要副本的查询存储
- 使用回归查询功能
- 查找正在等待的查询
- 配置选项
- 相关视图、函数和过程
- 查询存储函数
- 查询存储目录视图
- 查询存储的存储过程
- 查询存储维护
- 性能审核和疑难解答
- 更改数据库兼容性级别和使用查询存储
- 使用最新版 SQL Server Management Studio
- 在 Azure SQL 数据库中使用 Query Performance Insight
- 将查询存储与弹性池数据库配合使用
- 开始进行查询性能故障排除
- 确保查询存储持续收集查询数据
- 错误状态
- 避免使用非参数化查询
- 在查询存储中查找非参数化查询
- 避免对包含对象使用 DROP 和 CREATE 模式
- 定期检查强制计划的状态
- 避免在使用强制计划执行查询时重命名数据库
- 在任务关键型服务器中使用查询存储
- 在 Azure SQL 数据库活动异地复制中使用查询存储
- 始终根据工作负载调整查询存储
- 性能优化示例查询
- 在数据库上执行的最后一个查询
- 执行计数
- 最长平均执行时间
- 最大平均物理 I/O 读取数
- 具有多个计划的查询
- 最长等待持续时间
- 最近具有性能回归的查询
- 具有历史性能回归的查询
- 维护查询性能稳定性
- 强制执行查询计划(应用强制策略)
- 计划强制支持快进和静态游标
- 删除为查询强制执行的计划
- Azure SQL 数据库中的查询存储默认值
- 设置最佳查询存储捕获模式
- 在 Query Store 中保留最相关数据
- 自定义捕获策略
- 自定义捕获策略示例
- 查询存储最大大小
- 数据刷新间隔(分钟)
- 修改查询存储默认值
- 查看查询存储当前设置
- 示例
- 查询存储维护
- 查询存储状态
- 获取查询存储选项
- 设置查询存储间隔
- 查询存储空间使用情况
- 获取查询存储选项
- 清理空间
- 删除临时查询
- 概述
- 何时使用查询存储提示
- 查询存储提示系统存储过程
- 执行计划 XML 特性
- 查询存储提示和功能互操作性
- 查询存储提示和可用性组
- 查询存储提示最佳做法
- 示例
- A. 查询存储提示演示
- B. 在查询存储中标识查询
- 查询存储提示的用例
- 无法更改代码时
- 在高事务负载下或使用任务关键型代码
- 作为计划指南的替代方案
- 考虑较新的兼容性级别
- 升级后考虑旧的兼容性级别
- 查询存储提示注意事项
- 数据分发更改
- 定期重新评估查询存储提示策略
- 广泛的潜在影响
- 强制参数化和 RECOMPILE 提示不受支持
- 找出并解决使用计划选择回归的查询
- 确定和优化排名靠前的资源占用查询
- A/B 测试
- 在升级到新版 SQL Server 期间保持性能稳定
- 识别并改进临时工作负载
- SQL总结
- 所有库的查询重写配置查询
- 查询存储函数
- 查询存储目录视图
- 查询存储的存储过程
引言
SQLServer 2016版起,微软添加此功能可以方便的检索慢查询,功能名称:查询存储!
查询存储可以解决的问题:
- 系统本番前后遇到的语句性能问题
- 语句在执行中发生的执行计划的变换
- 语句执行中使用的性能百分比
- 查找SQL语句缺失的索引的问题
- 快速分析目前服务器中的语句性能维度
使用查询存储来监视性能
简介
查询存储功能提供有关 SQL Server、Azure SQL 数据库、Azure SQL 托管实例和 Azure Synapse Analytics 的查询计划选择和性能的见解。 查询存储可帮助你快速找到查询计划更改所造成的性能差异,从而简化性能疑难解答。 查询存储将自动捕获查询、计划和运行时统计信息的历史记录,并保留它们以供查阅。 它按时间窗口将数据分割开来,使你可以查看数据库使用模式并了解服务器上何时发生了查询计划更改。 可以使用 ALTER DATABASE SET 选项来配置查询存储。
- 有关在 Azure SQL 数据库中运行查询存储的信息,请参阅 在 Azure SQL 数据库中运行查询存储。
- 若要详细了解如何使用查询存储发现可操作信息并优化性能,请参阅使用查询存储优化性能。
若要详细了解如何在不更改应用程序代码的情况下调整查询计划,请参阅查询存储提示。
重要
如果仅对 SQL Server 2016 (13.x) 中正在运行的工作负载见解使用查询存储,请尽快安装 KB 4340759 中的性能可伸缩性修补程序。
查询存储存储过程
- sp_query_store_flush_db (Transact-SQL)
- sp_query_store_force_plan (Transact-SQL)
- sp_query_store_remove_plan (Transact-SQL)
- sp_query_store_remove_query (Transact-SQL)
- sp_query_store_reset_exec_stats (Transact-SQL)
- sp_query_store_unforce_plan (Transact-SQL)
- sp_query_store_set_hints (Transact-SQL)
- sp_query_store_clear_message_queues (Transact-SQL)
目录视图
- sys.database_query_store_options (Transact-SQL)
- sys.query_context_settings (Transact-SQL)
- sys.query_store_plan (Transact-SQL)
- sys.query_store_query (Transact-SQL)
- sys.query_store_query_text (Transact-SQL)
- sys.query_store_wait_stats (Transact-SQL)
- sys.query_store_runtime_stats (Transact-SQL)
- sys.query_store_runtime_stats_interval (Transact-SQL)
- sys.query_store_query_hints (Transact-SQL)
- sys.database_query_store_internal_state (Transact-SQL)
启用查询存储
- 默认将为新的 Azure SQL 数据库和 Azure SQL 托管实例数据库启用查询存储。
- 默认不会为 SQL Server 2016 (13.x)、SQL Server 2017 (14.x)、SQL Server 2019 (15.x) 启用查询存储。 对于从 SQL Server 2022 (16.x) 开始的新数据库,默认情况下在
READ_WRITE模式下启用它。 若要启用功能以更好地跟踪性能历史记录、排查查询计划相关问题并在 SQL Server 2022 (16.x) 中启用新功能,建议在所有数据库上启用查询存储。 - 默认不为新的 Azure Synapse Analytics 数据库启用查询存储。
使用 SQL Server Management Studio 中的“查询存储”页面
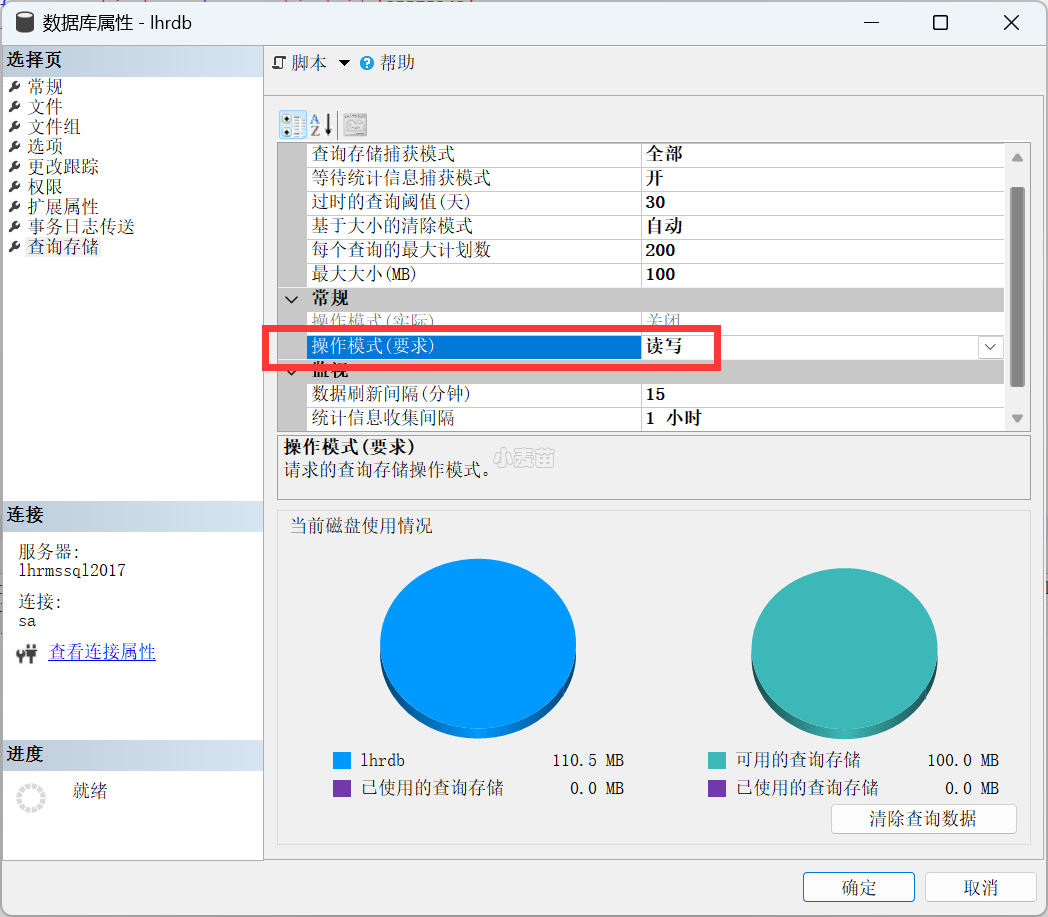
在对象资源管理器中,右键单击数据库,然后选择“属性”。
备注:至少需要 16 版本的 Management Studio。
在“数据库属性” 对话框中,选择“查询存储” 页。
在“操作模式(要求)”对话框中,选择“读写”。
使用 Transact-SQL 语句
使用 ALTER DATABASE 语句启用给定数据库的查询存储。 例如:
1 2 | ALTER DATABASE <database_name> SET QUERY_STORE = ON (OPERATION_MODE = READ_WRITE); |
在 Azure Synapse Analytics 中,无需其他选项即可启用查询存储,例如:
1 2 | ALTER DATABASE <database_name> SET QUERY_STORE = ON; |
有关与查询存储相关的语法选项的详细信息,请参阅 ALTER DATABASE SET 选项 (Transact-SQL)。
备注
无法为 master 或 tempdb 数据库启用查询存储。
重要
有关启用查询存储并使其适用于你的工作负载,请参阅查询存储最佳做法。
查询存储中的信息
由于统计信息更改、架构更改、索引的创建/删除等多种不同原因,SQL Server 中任何特定查询的执行计划通常会随着时间而改进。过程缓存(其中存储了缓存的查询计划)仅存储最近的执行计划。 还会由于内存压力从计划缓存中逐出计划。 因此,执行计划更改造成的查询性能回归可能非常重大,且长时间才能解决。
由于查询存储会保留每个查询的多个执行计划,因此它可以强制执行策略,以引导查询处理器对某个查询使用特定执行计划。 这称为“计划强制”。 查询存储中的计划强制是通过使用类似于 USE PLAN 查询提示的机制来提供的,但它不需要在用户应用程序中进行任何更改。 计划强制可在非常短的时间内解决由计划更改造成的查询性能回归。
备注
查询存储收集 DML 语句(如 SELECT、INSERT、UPDATE、DELETE、MERGE 和 BULK INSERT)的计划。
根据设计,查询存储不会收集 CREATE INDEX 等 DDL 语句的计划。查询存储通过收集基础 DML 语句的计划来捕获累积资源消耗。 例如,查询存储可能会显示在内部执行的 SELECT 和 INSERT 语句以填充新索引。
默认情况下,查询存储不对本机编译的存储过程收集数据。 使用 sys.sp_xtp_control_query_exec_stats 为本机编译的存储过程启用数据收集。
等待统计信息是有助于排除数据库引擎中的性能问题的另一信息来源。 长期以来,等待统计信息仅适用于实例级别,难以回溯到特定查询。 从 SQL Server 2017(14.x)和 Azure SQL 数据库开始,查询存储包含一个跟踪等待统计信息的维度。下面的示例允许查询存储收集等待统计信息。
1 2 | ALTER DATABASE <database_name> SET QUERY_STORE = ON ( WAIT_STATS_CAPTURE_MODE = ON ); |
使用查询存储功能的常见方案为:
- 快速查找并修复通过强制使用先前查询计划而造成的计划性能回归。 修复近期由于执行计划更改而出现性能回归的查询。
- 确定在给定时间窗口中查询执行的次数,从而帮助 DBA 对性能资源问题进行故障排除。
- 标识过去 x 小时内的前 n 个查询(按执行时间、内存占用等)。
- 审核给定查询的查询计划历史记录。
- 分析特定数据库的资源(CPU、I/O 和内存)使用模式。
- 确定资源上正在等待的前 n 个查询。
- 了解特定查询或计划的等待性质。
查询存储包含三个存储:
- 计划存储:用于保存执行计划信息。
- 运行时统计信息存储:用于保存执行统计信息。
- 等待统计信息存储:用于保存等待统计信息。
max_plans_per_query 配置选项限制了计划存储中查询可存储的唯一计划数。 为增强性能,通过异步方式向存储写入信息。 为尽量减少空间使用量,将在按固定时间窗口上聚合运行时统计信息存储中的运行时执行统计信息。 可通过查询查询存储目录视图来查看这些存储中的信息。
以下查询返回查询存储中查询和计划的相关信息。
1 2 3 4 5 6 | SELECT Txt.query_text_id, Txt.query_sql_text, Pl.plan_id, Qry.* FROM sys.query_store_plan AS Pl INNER JOIN sys.query_store_query AS Qry ON Pl.query_id = Qry.query_id INNER JOIN sys.query_store_query_text AS Txt ON Qry.query_text_id = Txt.query_text_id; |
次要副本的查询存储
适用于:SQL Server(SQL Server 2022 (16.x) 及更高版本)
次要副本的查询存储功能在次要副本工作负载上启用可用于主要副本的相同的查询存储功能。 启用次要副本的查询存储后,副本会将通常存储在查询存储中的查询执行信息发送回主要副本。 然后,主要副本会将数据保存到自身查询存储中的磁盘。 从本质上讲,主要副本和所有次要副本之间共享有一个查询存储。 查询存储存在于主要副本上,将所有副本的数据一起存储。
有关次要副本的查询存储的完整信息,请参阅 Always On 可用性组次要副本的查询存储。
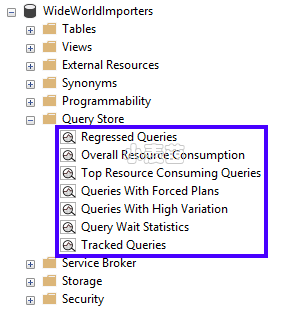
使用回归查询功能
在启用查询存储后,刷新对象资源管理器窗格的数据库部分,以添加“查询存储”部分。
备注
对于 Azure Synapse Analytics,查询存储视图位于对象资源管理器窗格数据库部分的“系统视图”下。
选择“回归查询”,以在 SQL Server Management Studio 中打开“回归查询”窗格。 “回归查询”窗格将显示查询存储中的查询和计划。 使用顶部的下拉列表框,根据各种条件筛选查询:持续时间 (ms)(默认)、CPU 时间 (ms)、逻辑读取 (KB)、逻辑写入 (KB)、物理读取 (KB)、CLR 时间 (ms)、DOP、内存消耗 (KB)、行计数、已用日志内存 (KB)、已用临时 DB 内存 (KB) 和等待时间 (ms)。
选择某个计划以查看图形查询计划。 可以使用按钮查看源查询、强制执行和取消强制执行查询计划、在网格和图表格式之间进行切换、比较所选的计划(如果选择多个)及刷新显示。
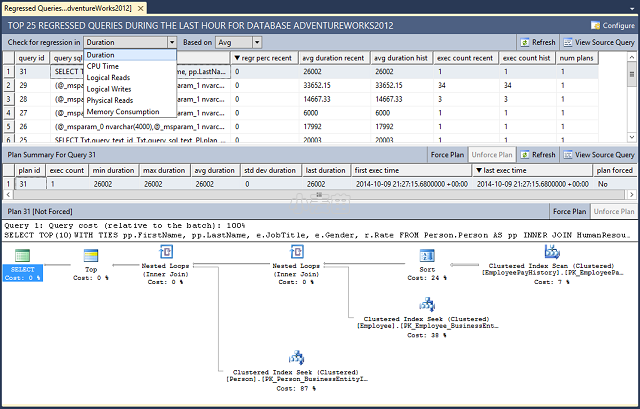
若要强制执行某一计划,请选择查询和计划,然后选择“强制计划”。 你只可以强制执行由查询计划功能保存且仍保留在查询计划缓存中的计划。
查找正在等待的查询
从 SQL Server 2017 (14.x) 和 Azure SQL 数据库开始,查询存储中提供了一段时间内每个查询的等待统计信息。
在查询存储中,等待类型将合并到等待类别中。 sys.query_store_wait_stats (Transact-SQL) 中提供从等待类别到等待类型的映射。
在 SQL Server Management Studio v18 或更高版本中,选择“查询等待统计信息”以打开“查询等待统计信息”窗格。 “查询等待统计信息”窗格显示包含查询存储中排在前面的等待类别的条形图。 使用顶部的下拉列表选择等待时间的聚合条件:平均值、最大值、最小值、标准偏差和总计(默认)。
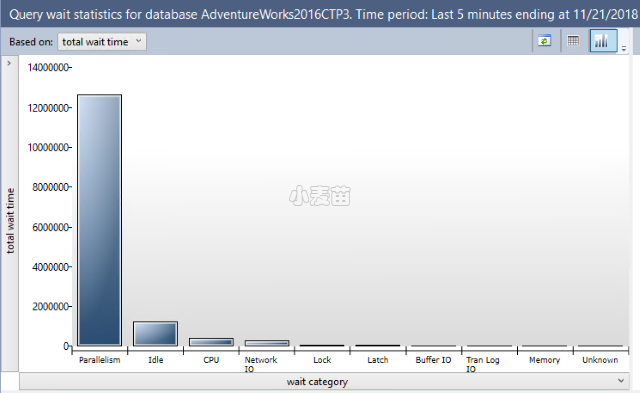
通过选择条形图和所选等待类别展示的详细信息视图,选择等待类别。 这个新的条形图包含对该等待类别有贡献的查询。
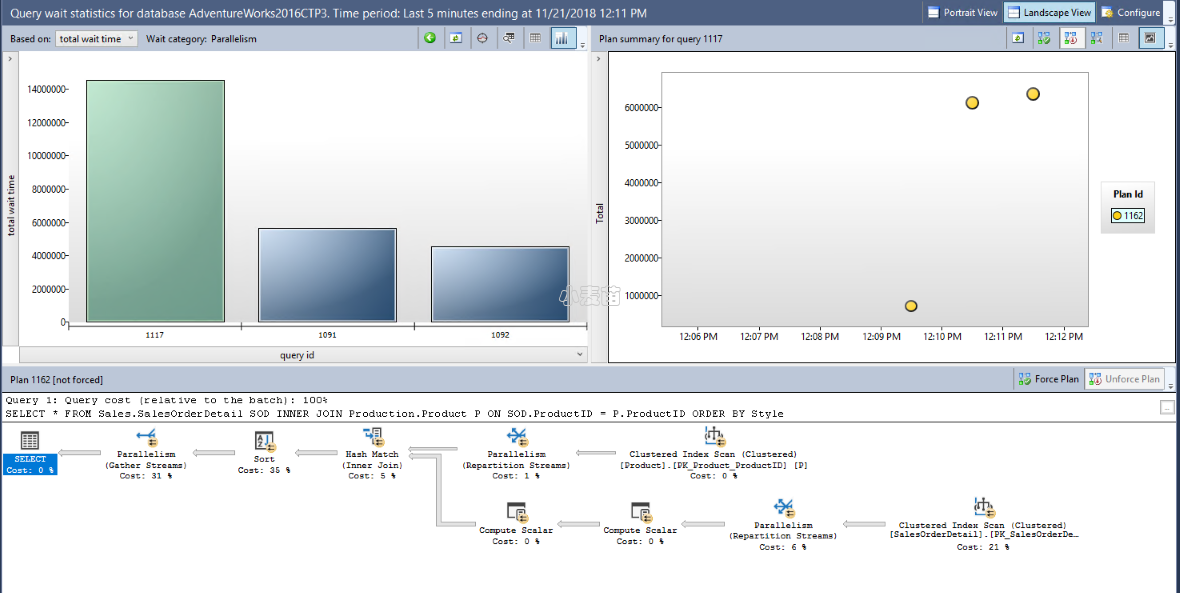
使用顶部的下拉列表框,根据各种等待时间条件为所选等待类别筛选查询:平均值、最大值、最小值、标准偏差和总计(默认)。 选择某个计划以查看图形查询计划。 可使用按钮来查看源查询,强制执行和取消强制执行某一查询计划,以及刷新显示内容。
等待类别可将不同等待类型按性质合并为类似的桶。 不同的等待类别需要不同的后续分析才能解决此问题,但相同类别的等待类型可引起非常相似的故障排除体验,并假定基于等待的受影响的查询会成为用于成功完成大部分此类调查所缺少的部分。
下面的示例介绍如何在查询存储中引入等待类别前后更深入了解工作负荷:
| 曾经的体验 | 新的体验 | 操作 |
|---|---|---|
| 每个数据库的高 RESOURCE_SEMAPHORE 等待 | 特定查询在查询存储中的高内存等待 | 在查询存储中查找消耗内存最多的查询。 这些查询可能会延迟受影响查询的进度。 请考虑对这些查询或受影响的查询使用 MAX_GRANT_PERCENT 查询提示。 |
| 每个数据库的高 LCK_M_X 等待 | 特定查询在查询存储中的高锁定等待 | 检查受影响查询的查询文本,并确定目标实体。 在查询存储中查找修改同一实体的其他查询,该实体频繁执行和/或具有较高持续时间。 确定这些查询后,请考虑更改应用程序逻辑以提高并发性,或使用限制较少的隔离级别。 |
| 每个数据库的高 PAGEIOLATCH_SH 等待 | 特定查询在查询存储中的高缓冲 IO 等待 | 在查询存储中查找具有大量物理读取的查询。 如果它们与含较高 IO 等待的查询匹配,执行执行搜索而不是扫描时,请考虑引入关于基础实体的索引,以便减少查询的 IO 开销。 |
| 每个数据库的高 SOS_SCHEDULER_YIELD 等待 | 特定查询在查询存储中的高 CPU 等待 | 查找查询存储中前几个使用 CPU 最多的查询。 其中,请确定其高 CPU 趋势与受影响查询的高 CPU 等待关联的查询。 重点优化这些查询 - 可能存在计划回归,或缺失的索引。 |
配置选项
有关配置查询存储参数的可用选项,请参阅 ALTER DATABASE SET 选项 (Transact-SQL)。
查询 sys.database_query_store_options 视图以确定查询存储的当前选项。 有关值的详细信息,请参阅 sys.database_query_store_options。
有关使用 Transact-SQL 语句来设置配置选项的示例,请参阅选项管理。
备注
对于 Azure Synapse Analytics,可以像其他平台一样启用查询存储,但不支持其他配置选项。
相关视图、函数和过程
通过 Management Studio 或使用以下视图和过程来查看和管理查询存储。
查询存储函数
此函数有助于执行查询存储操作。
sys.fn_stmt_sql_handle_from_sql_stmt (Transact-SQL)
查询存储目录视图
目录视图提供了查询存储的相关信息。
sys.database_query_store_options (Transact-SQL)
sys.query_context_settings (Transact-SQL)
sys.query_store_plan (Transact-SQL)
sys.query_store_query (Transact-SQL)
sys.query_store_query_text (Transact-SQL)
sys.query_store_runtime_stats (Transact-SQL)
sys.query_store_wait_stats (Transact-SQL)
sys.query_store_runtime_stats_interval (Transact-SQL)
sys.database_query_store_internal_state (Transact-SQL)
查询存储的存储过程
存储过程配置了查询存储。
sp_query_store_flush_db (Transact-SQL)
sp_query_store_reset_exec_stats (Transact-SQL)
sp_query_store_force_plan (Transact-SQL)
sp_query_store_unforce_plan (Transact-SQL)
sp_query_store_remove_plan (Transact-SQL)
sp_query_store_remove_query (Transact-SQL)
sp_query_store_clear_message_queues (Transact-SQL)
sp_query_store_consistency_check (Transact-SQL)1
1 在极端情况下,查询存储可能由于内部错误而进入 ERROR 状态。 从 SQL Server 2017 (14.x) 开始,如果出现这种情况,可通过在受影响的数据库内执行 sp_query_store_consistency_check 存储过程来恢复查询存储。 请参阅 sys.database_query_store_options,了解 actual_state_desc 列说明中所述的详细信息。
查询存储维护
本文扩展了有关查询存储维护和管理的最佳做法和建议:管理查询存储的最佳做法。
性能审核和疑难解答
有关深入了解如何使用查询存储来优化性能的详细信息,请参阅使用查询存储优化性能。
其他性能主题:
更改数据库兼容性级别和使用查询存储
从 SQL Server 2016 (13.x) 及更高版本,某些更改仅在数据库兼容级别更改后才会启用。 执行此操作的原因如下:
- 由于升级是单向操作(不可能降级文件格式),将新功能的启用分离为数据库内的单独操作有一定作用。 可以将一项设置还原到之前的数据库兼容性级别。 新的模式可以减少中断期间必然发生的事件的数量。
- 更改查询处理器可能会产生复杂的影响。 即使对系统进行的是“较好的”更改(对大多数工作负荷而言可能是非常好的更改),也可能对其他工作负荷的重要查询造成不可接受的回归。 通过从升级过程中分离此逻辑,查询存储等功能可在生产服务器中快速缓解计划选择回归或甚至完全将其规避。
附加或还原数据库时以及就地升级后,SQL Server 2017 (14.x) 应出现以下行为:
- 如果升级前用户数据库的兼容级别为 100 或更高,升级后将保持相应级别。
- 如果升级前用户数据库的兼容级别为 90,则在升级后的数据库中,兼容级别将设置为 100,该级别为 SQL Server 2017 (14.x) 支持的最低兼容级别。
- 升级后,
tempdb、model、msdb和 Resource 数据库的兼容性级别将设置为当前兼容性级别。 master系统数据库保留它在升级之前的兼容级别。
用于启用新查询处理器功能的升级过程与产品的发布后服务模式相关。 这些修补程序中的一部分发布在跟踪标志 4199 下。 需要修补程序的客户可以选择加入这些修补程序而不会导致其他客户的意外回归。 查询处理器修补程序的发布后服务模式记录于 此处。 从 SQL Server 2016 (13.x) 开始,转换到新的兼容性级别意味着不再需要跟踪标志 4199,因为在最新的兼容性级别中,这些修补程序现在默认启用。 因此,作为升级过程的一部分,验证升级过程完成后未启用 4199 是很重要的。
备注
仍需要跟踪标志 4199 才能启用 RTM 之后发布的任何适用的新查询处理器修补程序。
查询存储使用方案中的“在升级到新版 SQL Server 期间保持性能稳定”部分中介绍了将查询处理器升级到最新版本的建议工作流,如下所示。

自 SQL Server Management Studio v18 起,用户可借助查询优化助手按指导操作建议的工作流。 有关详细信息,请参阅[使用查询优化助手升级
数据库。
使用查询存储监视工作负载的最佳做法
本文概述使用 SQL Server 查询存储处理工作负载的最佳做法。
- 若要详细了解如何使用查询存储进行配置和管理,请参阅使用查询存储监视性能。
- 如需详细了解如何使用查询存储发现可操作信息并优化性能,请参阅使用查询存储优化性能。
- 有关在 Azure SQL 数据库中运行查询存储的信息,请参阅 在 Azure SQL 数据库中运行查询存储。
- 在 Azure Synapse Analytics 中,默认情况下,不会为专用 SQL 池启用查询存储,但可以启用。 不支持查询存储的其他配置选项。 有关详细信息,请参阅 Azure Synapse Analytics 中的历史查询存储和分析。
使用最新版 SQL Server Management Studio
SQL Server Management Studio 提供了一组用户界面,旨在配置查询存储和使用收集的工作负载数据。 下载 SQL Server Management Studio 的最新版本。
有关如何使用查询存储进行故障排除的简要说明,请参阅Query Store Azure blogs。
在 Azure SQL 数据库中使用 Query Performance Insight
如果在 Azure SQL 数据库中运行查询存储,则可使用 Query Performance Insight 来分析一定时段内的资源消耗情况。 虽然可以使用 Management Studio 和 Azure Data Studio 来获取所有查询的详细资源消耗情况(例如 CPU、内存和 I/O),但使用 Query Performance Insight 可以快速且有效地确定查询对数据库总体 DTU 消耗情况的影响。 有关详细信息,请参阅 Azure SQL Database Query Performance Insight(Azure SQL 数据库的 Query Performance Insight)。
将查询存储与弹性池数据库配合使用
可以毫无顾忌地在所有数据库中使用 Query Store,甚至是在密集打包的 Azure SQL 数据库弹性池中。 之前与资源过度使用(为弹性池中的大量数据库启用了查询存储时可能会遇到这种情况)相关的所有问题都已得到了解决。
开始进行查询性能故障排除
查询存储工作流的故障排除很简单,如下图所示:

按上一节的说明通过 Management Studio 来启用查询存储,或者执行以下 Transact-SQL 语句:
SQL
1 | ALTER DATABASE [DatabaseOne] SET QUERY_STORE = ON; |
查询存储收集能够准确代表工作负载的数据集需要一定的时间。 通常情况下,即使是很复杂的工作负荷,一天的时间也足够了。 但是,在启用此功能后,就可以立即开始浏览数据并确定需要注意的查询。 转到 Management Studio 的对象资源管理器中数据库节点下的查询存储子文件夹,然后打开特定方案的故障排除视图。
Management Studio Query Store 视图在操作时使用一组执行度量值,每个度量值都表示为下述任意统计函数:
展开表
| SQL Server 版本 | 执行度量值 | 统计函数 |
|---|---|---|
| SQL Server 2016 (13.x) | CPU 时间、持续时间、执行计数、逻辑读取次数、逻辑写入次数、内存消耗、物理读取次数、CLR 时间、并行度 (DOP) 和行计数 | 平均值、最大值、最小值、标准偏差、总数 |
| SQL Server 2017 (14.x) | CPU 时间、持续时间、执行计数、逻辑读取次数、逻辑写入次数、内存消耗、物理读取次数、CLR 时间、并行度、行计数、日志内存、TempDB 内存和等待时间 | 平均值、最大值、最小值、标准偏差、总数 |
下图显示了如何查找 Query Store 视图:
下表说明了何时使用每个 Query Store 视图:
展开表
| SQL Server Management Studio | 方案 |
|---|---|
| 回归查询 | 查明哪些查询的执行度量值最近进行了回归(例如,变得更糟)。 使用此视图将应用程序中观察到的性能问题与需要进行修复或改进的实际查询关联起来。 |
| 总体资源消耗 | 针对任意执行度量值分析数据库的总资源消耗量。 使用此视图可以确定资源模式(白天工作负荷与夜间工作负荷的比较),并优化数据库的总体消耗。 |
| 资源使用排名靠前的查询 | 选择所关注的执行度量值,确定在指定的时间间隔内具有最极端值的查询。 此视图可以帮助你关注最相关的查询,这些查询对数据库资源消耗的影响最大。 |
| 具有强制计划的查询 | 使用查询存储列出以前的强制计划。 使用此视图快速访问当前的所有强制计划。 |
| 变化程度高的查询 | 分析执行变化程度较高的查询,此类变化可涉及任何可用的维度,例如所需时间间隔内的持续时间、CPU 时间、IO 和内存使用情况。 使用此视图可以标识性能有很大差异且可能会影响用户跨应用程序体验的查询。 |
| 查询等待统计信息 | 分析数据库中最活跃的等待类别和对所选等待类别贡献最大的查询。 使用此视图分析等待统计信息并识别可能在应用程序中影响用户体验的查询。 适用于:从 SQL Server Management Studio v18.0 和 SQL Server 2017 (14.x) 开始。 |
| 跟踪的查询 | 实时跟踪最重要查询的执行情况。 通常情况下,使用此视图是因为你计划强制执行相关查询,因此需确保查询性能的稳定性。 |
提示
如需详细了解如何使用 Management Studio 来确定资源使用排名靠前的查询并修复那些因计划选择变化而导致回归的查询,请参阅 Query Store Azure Blogs。
如果确定某个查询的性能不够理想,则可根据问题性质进行操作。
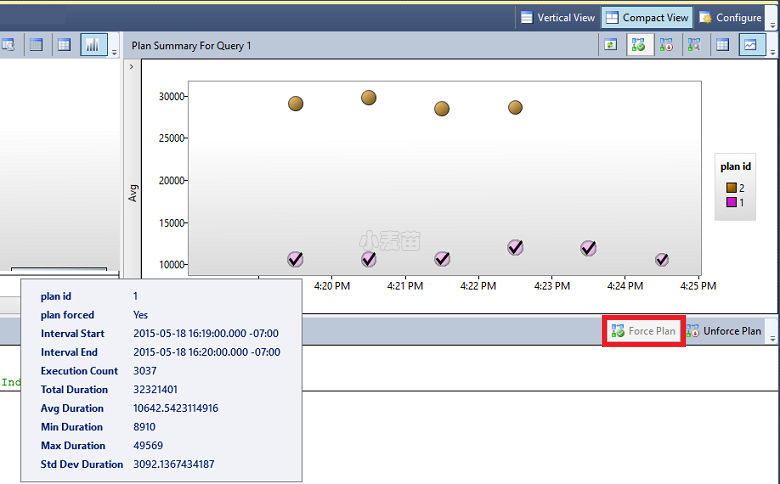
如果所执行的查询具有多个计划,而最后一个计划明显不如前面的计划,则可通过计划强制机制来强制使用最佳计划。 SQL Server 尝试强制实施优化器中的计划。 如果计划强制实施失败,将触发 XEvent,并指示优化器正常优化。

备注
前面的图形针对特定的查询计划会显示不同的形状,以下是可能出现的每种形状的对应含义:
展开表
形状 含义 圆形 查询已完成,这意味着常规执行成功完成。 平方 已取消,这意味着客户端发起的执行中止。 三角形 失败,这意味着异常执行中止。 此外,形状大小反映指定时间间隔内的查询执行计数。 如果执行次数较多,该形状会变大。
你可以认为,你的查询因为缺少索引而无法达到最佳执行效果。 此信息显示在查询执行计划中。 使用查询存储创建缺失的索引并检查查询性能。

如果你在 SQL 数据库上运行工作负载,可注册获取 SQL 数据库索引顾问,然后即可自动接收索引建议。
- 在某些情况下,如果你看到执行计划中估计的行数和实际的行数存在显著差异,则可强制执行统计信息的重新编译。
重写有问题的查询,例如可以充分利用查询参数化或实现更优化的逻辑。
提示
在 Azure SQL 数据库中,考虑使用查询存储提示功能,该功能可以在不更改代码的情况下对查询强制执行查询提示。 有关详细信息和示例,请参阅查询存储提示。
确保查询存储持续收集查询数据
查询存储可在无提示的情况下更改操作模式。 请定期监视查询存储的状态以确保查询存储正常运行,并采取相应措施,避免发生不必要的故障。 执行以下查询,以便确定操作模式并查看最相关的参数:
1 2 3 4 5 6 7 8 | USE [QueryStoreDB]; GO SELECT actual_state_desc, desired_state_desc, current_storage_size_mb, max_storage_size_mb, readonly_reason, interval_length_minutes, stale_query_threshold_days, size_based_cleanup_mode_desc, query_capture_mode_desc FROM sys.database_query_store_options; |
actual_state_desc 和 desired_state_desc 之间存在差异,这表明自动更改了操作模式。 最常见的更改是查询存储在无提示的情况下切换到只读模式。 在极罕见的情况下,查询存储可能会因内部错误而导致处于错误状态。
当实际状态为只读时,可使用 readonly_reason 列来确定根本原因。 通常情况下,你会发现,查询存储转换为只读模式是因为超出了大小配额。 在这种情况下,readonly_reason 设置为 65536。 有关其他原因,请参阅 sys.database_query_store_options (Transact-SQL)。
考虑执行以下步骤将 Query Store 切换为读写模式并激活数据收集功能:
使用
ALTER DATABASE的 MAX_STORAGE_SIZE_MB 选项增大最大存储大小。使用以下语句清理 Query Store 数据:
1ALTER DATABASE [QueryStoreDB] SET QUERY_STORE CLEAR;
在应用这两项或其中一项步骤时,可以执行以下语句,通过显式方式将操作模式改回为读写:
1 2 | ALTER DATABASE [QueryStoreDB] SET QUERY_STORE (OPERATION_MODE = READ_WRITE); |
采用以下前摄性步骤:
- 遵循最佳实践规范即可避免在无提示情况下更改操作模式。 如果可以确保查询存储大小始终小于最大允许值,则会极大地降低转换为只读模式的几率。 根据配置查询存储部分所述,可激活基于大小的策略,使查询存储在大小接近极限时自动清除数据。
- 为了确保最新的数据能够得到保留,可将基于时间的策略配置为定期删除过时信息。
- 最后,请考虑将“查询存储捕获模式”设置为“Auto”,因为这样通常可以筛选掉与工作负载不太相关的查询。
错误状态
若要恢复查询存储,可尝试以显式方式设置读写模式,然后再次检查实际状态。
SQL
1 2 3 4 5 6 7 8 9 | ALTER DATABASE [QueryStoreDB] SET QUERY_STORE (OPERATION_MODE = READ_WRITE); GO SELECT actual_state_desc, desired_state_desc, current_storage_size_mb, max_storage_size_mb, readonly_reason, interval_length_minutes, stale_query_threshold_days, size_based_cleanup_mode_desc, query_capture_mode_desc FROM sys.database_query_store_options; |
如果问题仍然存在,则表明磁盘上的查询存储数据已永久损坏。
从 SQL Server 2017 (14.x) 开始,可通过在受影响的数据库内执行 sys.sp_query_store_consistency_check 存储过程来恢复查询存储。 必须先禁用查询存储,然后才能尝试恢复操作。 可使用或修改以下示例查询,完成 QDS 的一致性检查和恢复:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | IF EXISTS (SELECT * FROM sys.database_query_store_options WHERE actual_state=3) BEGIN BEGIN TRY ALTER DATABASE [QDS] SET QUERY_STORE = OFF Exec [QDS].dbo.sp_query_store_consistency_check ALTER DATABASE [QDS] SET QUERY_STORE = ON ALTER DATABASE [QDS] SET QUERY_STORE (OPERATION_MODE = READ_WRITE) END TRY BEGIN CATCH SELECT ERROR_NUMBER() AS ErrorNumber ,ERROR_SEVERITY() AS ErrorSeverity ,ERROR_STATE() AS ErrorState ,ERROR_PROCEDURE() AS ErrorProcedure ,ERROR_LINE() AS ErrorLine ,ERROR_MESSAGE() AS ErrorMessage; END CATCH; END |
对于 SQL Server 2016 (13.x),需要从查询存储中清除数据,如下所示。
如果恢复失败,可先尝试清除查询存储,然后再设置读写模式。
1 2 3 4 5 6 7 8 9 10 11 12 13 | ALTER DATABASE [QueryStoreDB] SET QUERY_STORE CLEAR; GO ALTER DATABASE [QueryStoreDB] SET QUERY_STORE (OPERATION_MODE = READ_WRITE); GO SELECT actual_state_desc, desired_state_desc, current_storage_size_mb, max_storage_size_mb, readonly_reason, interval_length_minutes, stale_query_threshold_days, size_based_cleanup_mode_desc, query_capture_mode_desc FROM sys.database_query_store_options; |
避免使用非参数化查询
在不必要的情况下使用非参数化查询不是最佳做法。 临时分析就是一个示例。 不能重复使用缓存的计划,因为这会强制查询优化器在碰到每个唯一的查询文本时都进行查询编译。 有关详细信息,请参阅强制参数化使用指南。
此外,查询存储可能会很快超过大小配额,因为可能会存在大量不同的查询文本,导致存在大量不同但具有相同形状的执行计划。 结果就是,工作负载性能无法优化,查询存储可能会切换为只读模式,或者可能会不断删除数据以应对传入的查询。
请考虑以下选项:
在适用时进行参数化查询。 例如,在存储过程或
sp_executesql中包装查询。 有关详细信息,请参阅参数和执行计划重用。如果工作负载包含许多一次性使用的临时批处理且查询计划各不相同,请使用
针对临时工作负载进行优化
选项。
- 将不同 query_hash 值的数目与
sys.query_store_query中项的总数进行比较。 如果该比率接近 1,则说明临时工作负载生成了不同的查询。
- 将不同 query_hash 值的数目与
如果不同查询计划的数量不多,请对数据库或部分查询应用
强制参数化
。
- 请参阅计划指南,仅对选定查询强制执行参数化操作。
- 如果工作负载中不同查询计划的数目很小,则使用 parameterization database option 命令配置强制的参数化操作。 例如,当不同 query_hash 的计数与
sys.query_store_query中项的总数之比远小于 1 时。
将 QUERY_CAPTURE_MODE 设置为 AUTO 即可自动筛选掉资源消耗小的即席查询。
提示
使用对象关系映射 (ORM) 解决方案(如实体框架 (EF))时,手动 LINQ 查询树或某些原始 SQL 查询等应用程序查询可能不会参数化,这会影响计划重新使用以及在查询存储中跟踪查询的能力。 有关详细信息,请参阅 EF 查询缓存和参数化以及 EF 原始 SQL 查询。
在查询存储中查找非参数化查询
可以使用以下查询,使用查询存储 DMV,在 SQL Server、Azure SQL 托管实例或 Azure SQL 数据库中查找存储在查询存储中的计划数量:
SQL
1 2 3 4 5 6 7 8 | SELECT count(Pl.plan_id) AS plan_count, Qry.query_hash, Txt.query_text_id, Txt.query_sql_text FROM sys.query_store_plan AS Pl INNER JOIN sys.query_store_query AS Qry ON Pl.query_id = Qry.query_id INNER JOIN sys.query_store_query_text AS Txt ON Qry.query_text_id = Txt.query_text_id GROUP BY Qry.query_hash, Txt.query_text_id, Txt.query_sql_text ORDER BY plan_count desc; |
以下示例创建一个扩展事件会话来捕获事件 query_store_db_diagnostics,这在诊断查询资源消耗方面很有用。 在 SQL Server 中,此扩展事件会话会默认在 SQL Server 日志文件夹中创建一个事件文件。 例如,在 Windows 上默认安装 SQL Server 2019 (15.x) 时,会在文件夹 C:\Program Files\Microsoft SQL Server\MSSQL15.MSSQLSERVER\MSSQL\Log 中创建事件文件(.xel 文件)。 对于 Azure SQL 托管实例,请改为指定 Azure Blob 存储位置。 有关详细信息,请参阅 Azure SQL 托管实例的 XEvent event_file。 事件“qds.query_store_db_diagnostics”不适用于 Azure SQL 数据库。
SQL
1 2 3 4 5 | CREATE EVENT SESSION [QueryStore_Troubleshoot] ON SERVER ADD EVENT qds.query_store_db_diagnostics( ACTION(sqlos.system_thread_id,sqlos.task_address,sqlos.task_time,sqlserver.database_id,sqlserver.database_name)) ADD TARGET package0.event_file(SET filename=N'QueryStore',max_file_size=(100)) WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=30 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=OFF); |
使用这些数据,可以查找查询存储中的计划计数,以及许多其他统计信息。 在事件数据中查找 plan_count、query_count、max_stmt_hash_map_size_kb 和 max_size_mb 列,了解使用的内存量和查询存储跟踪的计划数量。 如果计划计数高于正常值,则表示非参数化查询有所增加。 使用以下查询存储 DMV 查询查看查询存储中的参数化查询和非参数化查询。
对于参数化查询:
SQL
1 2 3 4 5 | SELECT qsq.query_id, qsqt.query_sql_text FROM sys.query_store_query AS qsq INNER JOIN sys.query_store_query_text AS qsqt ON qsq.query_text_id= qsqt.query_text_id WHERE qsq.query_parameterization_type<>0 or qsqt.query_sql_text like '%@%'; |
对于非参数化查询:
SQL
1 2 3 4 5 | SELECT qsq.query_id, qsqt.query_sql_text FROM sys.query_store_query AS qsq INNER JOIN sys.query_store_query_text AS qsqt ON qsq.query_text_id= qsqt.query_text_id WHERE query_parameterization_type=0; |
避免对包含对象使用 DROP 和 CREATE 模式
查询存储会将查询条目与包含对象(例如存储过程、函数和触发器)相关联。 重新创建包含对象时,会针对同一查询文本生成新的查询条目。 这会阻止你跟踪该查询在一定时段内的性能统计信息,并会使用计划强制机制。 若要避免这种情况,请尽可能使用 ALTER <object> 过程来更改包含对象定义。
定期检查强制计划的状态
可以方便地使用计划强制机制来修复关键查询的性能问题,使这些查询的结果更可预测。 与计划提示和计划指南一样,强制实施某项计划并不能确保在今后的执行过程中会用到它。 通常情况下,如果对数据库架构的更改导致执行计划所引用的对象被更改或删除,计划强制就会失败。 在这种情况下,SQL Server 会回退到重新编译查询,而强制失败的实际原因则显示在 sys.query_store_plan 中。 以下查询返回强制计划的相关信息:
SQL
1 2 3 4 5 6 7 8 | USE [QueryStoreDB]; GO SELECT p.plan_id, p.query_id, q.object_id as containing_object_id, force_failure_count, last_force_failure_reason_desc FROM sys.query_store_plan AS p JOIN sys.query_store_query AS q on p.query_id = q.query_id WHERE is_forced_plan = 1; |
有关原因的完整列表,请参阅 sys.query_store_plan。 你还可以使用 query_store_plan_forcing_failed XEvent 来跟踪和故障排除计划强制失败情况。
提示
在 Azure SQL 数据库中,考虑使用查询存储提示功能,该功能可以在不更改代码的情况下对查询强制执行查询提示。 有关详细信息和示例,请参阅查询存储提示。
避免在使用强制计划执行查询时重命名数据库
执行计划使用由三个部分组成的名称(例如 database.schema.object)来引用对象。
如果重命名数据库,计划强制就会失败,导致在执行所有后续的查询时都需要重新编译。
在任务关键型服务器中使用查询存储
全局跟踪标志 7745 和 7752 可用于使用查询存储来提高数据库的可用性。 有关更多信息,请参见跟踪标记。
- 跟踪标志 7745 会阻止以下默认行为:在可关闭 SQL Server 之前,查询存储将数据写入磁盘。 这意味着在
DATA_FLUSH_INTERVAL_SECONDS定义的时间窗口之前,已收集但尚未保留到磁盘的查询存储数据将会丢失。 跟踪标志 7752 启用了查询存储的异步加载。 这会使数据库变为联机状态,并且在查询存储完全恢复之前执行查询。 默认行为是同步加载查询存储。 默认行为可在恢复查询存储之前防止执行查询,但同时也可在数据集合中防止遗漏任何查询。
备注
从 SQL Server 2019 (15.x) 开始,此行为由引擎控制,跟踪标志 7752 不再有效。
重要
如果仅对 SQL Server 2016 (13.x) 中的实时工作负载见解使用查询存储,请尽快安装 SQL Server 2016 (13.x) SP2 CU2 (KB 4340759) 中的性能可伸缩性改进。 如果没有这些改进,则当数据库处于繁重的工作负载下时,可能会发生旋转锁争用,并且服务器性能可能会变慢。 特别是,你可能会发现 QUERY_STORE_ASYNC_PERSIST 旋转锁或 SPL_QUERY_STORE_STATS_COOKIE_CACHE 旋转锁上出现繁重的争用情况。 应用此改进后,查询存储将不再导致旋转锁争用。
重要
如果你在 SQL Server(SQL Server 2016 (13.x) 到 SQL Server 2017 (14.x))中使用查询存储来获取实时工作负载见解,请尽快在 SQL Server 2016 (13.x) SP2 CU15、SQL Server 2017 (14.x) CU23 和 SQL Server 2019 (15.x) CU9 中安装性能可伸缩性改进功能。 如果没有此改进,则当数据库处于繁重的即席工作负载下时,查询存储可能会占用大量内存,并且服务器性能可能会变慢。 应用此改进后,查询存储会对其各个组件可使用的内存量施加内部限制,并且可以自动将操作模式更改为只读,直到有足够的内存返回到数据库引擎。 请注意,不会记录查询存储内部内存限制,因为它们随时可能更改。
在 Azure SQL 数据库活动异地复制中使用查询存储
Azure SQL 数据库的辅助活动异地复制上的查询存储将是主要副本上的活动的只读副本。
避免在使用 Azure SQL 数据库异地复制时出现不匹配的层。 辅助数据库在大小方面应与主数据库相同或相近,并且应与主数据库处于同一服务层。 在 sys.dm_db_wait_stats 中查找 HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO 等待类型,该类型表示由于辅助延迟而导致主副本上的事务日志速率受限。
若要详细了解如何估计和配置活动异地复制的辅助 Azure SQL 数据库的大小,请参阅配置辅助数据库。
始终根据工作负载调整查询存储
本文扩展了有关配置和管理查询存储的最佳做法和建议:管理查询存储的最佳做法。
使用查询存储优化性能
SQL Server 查询存储功能提供在工作负载中发现和优化查询的功能,无论是通过 SQL Server Management Studio 可视化界面还是 T-SQL 查询。 本文详细介绍了如何获取可操作的信息来提高数据库中的查询性能,包括如何根据查询的使用情况统计信息和强制计划来标识查询。 还可以使用查询存储提示功能来识别查询并调整其查询计划,而无需更改应用程序代码。
- 有关如何收集此数据的详细信息,请参阅查询存储如何收集数据。
- 若要详细了解如何使用查询存储进行配置和管理,请参阅使用查询存储监视性能。
- 有关在 Azure SQL 数据库中运行查询存储的信息,请参阅 在 Azure SQL 数据库中运行查询存储。
性能优化示例查询
查询存储将保存整个查询过程中的编译历史记录和运行时度量,使你能询问有关工作负载的问题。
下面的示例查询可能对你的性能基线和查询性能调查有所帮助:
在数据库上执行的最后一个查询
在数据库上执行的最后 n 个查询:
1 2 3 4 5 6 7 8 9 10 | SELECT TOP 10 qt.query_sql_text, q.query_id, qt.query_text_id, p.plan_id, rs.last_execution_time FROM sys.query_store_query_text AS qt JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id JOIN sys.query_store_plan AS p ON q.query_id = p.query_id JOIN sys.query_store_runtime_stats AS rs ON p.plan_id = rs.plan_id ORDER BY rs.last_execution_time DESC; |
执行计数
每个查询的执行数量:
1 2 3 4 5 6 7 8 9 10 11 | SELECT q.query_id, qt.query_text_id, qt.query_sql_text, SUM(rs.count_executions) AS total_execution_count FROM sys.query_store_query_text AS qt JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id JOIN sys.query_store_plan AS p ON q.query_id = p.query_id JOIN sys.query_store_runtime_stats AS rs ON p.plan_id = rs.plan_id GROUP BY q.query_id, qt.query_text_id, qt.query_sql_text ORDER BY total_execution_count DESC; |
最长平均执行时间
过去一小时内具有最长平均执行时间的查询数量:
1 2 3 4 5 6 7 8 9 10 11 12 | SELECT TOP 10 rs.avg_duration, qt.query_sql_text, q.query_id, qt.query_text_id, p.plan_id, GETUTCDATE() AS CurrentUTCTime, rs.last_execution_time FROM sys.query_store_query_text AS qt JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id JOIN sys.query_store_plan AS p ON q.query_id = p.query_id JOIN sys.query_store_runtime_stats AS rs ON p.plan_id = rs.plan_id WHERE rs.last_execution_time > DATEADD(hour, -1, GETUTCDATE()) ORDER BY rs.avg_duration DESC; |
最大平均物理 I/O 读取数
在相应的平均行计数和执行计数下,过去 24 小时内具有最大平均物理 I/O 读取数的查询数量:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | SELECT TOP 10 rs.avg_physical_io_reads, qt.query_sql_text, q.query_id, qt.query_text_id, p.plan_id, rs.runtime_stats_id, rsi.start_time, rsi.end_time, rs.avg_rowcount, rs.count_executions FROM sys.query_store_query_text AS qt JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id JOIN sys.query_store_plan AS p ON q.query_id = p.query_id JOIN sys.query_store_runtime_stats AS rs ON p.plan_id = rs.plan_id JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id WHERE rsi.start_time >= DATEADD(hour, -24, GETUTCDATE()) ORDER BY rs.avg_physical_io_reads DESC; |
具有多个计划的查询
这些查询特别有趣,因为计划选择更改可能造成它们的性能回归。 以下查询将这些查询和所有计划一同进行了标识:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | WITH Query_MultPlans AS ( SELECT COUNT(*) AS cnt, q.query_id FROM sys.query_store_query_text AS qt JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id JOIN sys.query_store_plan AS p ON p.query_id = q.query_id GROUP BY q.query_id HAVING COUNT(distinct plan_id) > 1 ) SELECT q.query_id, object_name(object_id) AS ContainingObject, query_sql_text, plan_id, p.query_plan AS plan_xml, p.last_compile_start_time, p.last_execution_time FROM Query_MultPlans AS qm JOIN sys.query_store_query AS q ON qm.query_id = q.query_id JOIN sys.query_store_plan AS p ON q.query_id = p.query_id JOIN sys.query_store_query_text qt ON qt.query_text_id = q.query_text_id ORDER BY query_id, plan_id; |
最长等待持续时间
此查询将返回具有最长等待持续时间的前 10 个查询:
1 2 3 4 5 6 7 8 9 10 11 | SELECT TOP 10 qt.query_text_id, q.query_id, p.plan_id, sum(total_query_wait_time_ms) AS sum_total_wait_ms FROM sys.query_store_wait_stats ws JOIN sys.query_store_plan p ON ws.plan_id = p.plan_id JOIN sys.query_store_query q ON p.query_id = q.query_id JOIN sys.query_store_query_text qt ON q.query_text_id = qt.query_text_id GROUP BY qt.query_text_id, q.query_id, p.plan_id ORDER BY sum_total_wait_ms DESC; |
备注
在 Azure Synapse Analytics 中,本部分中的查询存储示例查询受支持,但等待统计信息除外,该信息在 Azure Synapse Analytics 查询存储 DMV 中不可用。
最近具有性能回归的查询
以下查询示例返回了其执行时间因计划选择更改而在过去 48 小时内翻倍的所有查询。 此查询会并排比较所有运行时统计信息时间间隔:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | SELECT qt.query_sql_text, q.query_id, qt.query_text_id, rs1.runtime_stats_id AS runtime_stats_id_1, rsi1.start_time AS interval_1, p1.plan_id AS plan_1, rs1.avg_duration AS avg_duration_1, rs2.avg_duration AS avg_duration_2, p2.plan_id AS plan_2, rsi2.start_time AS interval_2, rs2.runtime_stats_id AS runtime_stats_id_2 FROM sys.query_store_query_text AS qt JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id JOIN sys.query_store_plan AS p1 ON q.query_id = p1.query_id JOIN sys.query_store_runtime_stats AS rs1 ON p1.plan_id = rs1.plan_id JOIN sys.query_store_runtime_stats_interval AS rsi1 ON rsi1.runtime_stats_interval_id = rs1.runtime_stats_interval_id JOIN sys.query_store_plan AS p2 ON q.query_id = p2.query_id JOIN sys.query_store_runtime_stats AS rs2 ON p2.plan_id = rs2.plan_id JOIN sys.query_store_runtime_stats_interval AS rsi2 ON rsi2.runtime_stats_interval_id = rs2.runtime_stats_interval_id WHERE rsi1.start_time > DATEADD(hour, -48, GETUTCDATE()) AND rsi2.start_time > rsi1.start_time AND p1.plan_id <> p2.plan_id AND rs2.avg_duration > 2*rs1.avg_duration ORDER BY q.query_id, rsi1.start_time, rsi2.start_time; |
如果想查看所有回归的性能(而不仅是与计划选择更改相关的回归),请从前一个查询中删除条件 AND p1.plan_id <> p2.plan_id 。
具有历史性能回归的查询
下一个查询将最近的执行与历史执行进行比较,从而根据执行周期比较查询执行。 在此特定示例中,查询对比了最近时期(1 小时)和历史时期(过去一天)中的执行,并标识了引入 additional_duration_workload 的查询。 此度量的计算方式是最近平均执行和历史平均执行之差,再乘以最近执行数量。 它实际上表示相对于历史记录,引入了多少额外的持续时间最近执行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 | --- "Recent" workload - last 1 hour DECLARE @recent_start_time datetimeoffset; DECLARE @recent_end_time datetimeoffset; SET @recent_start_time = DATEADD(hour, -1, SYSUTCDATETIME()); SET @recent_end_time = SYSUTCDATETIME(); --- "History" workload DECLARE @history_start_time datetimeoffset; DECLARE @history_end_time datetimeoffset; SET @history_start_time = DATEADD(hour, -24, SYSUTCDATETIME()); SET @history_end_time = SYSUTCDATETIME(); WITH hist AS ( SELECT p.query_id query_id, ROUND(ROUND(CONVERT(FLOAT, SUM(rs.avg_duration * rs.count_executions)) * 0.001, 2), 2) AS total_duration, SUM(rs.count_executions) AS count_executions, COUNT(distinct p.plan_id) AS num_plans FROM sys.query_store_runtime_stats AS rs JOIN sys.query_store_plan AS p ON p.plan_id = rs.plan_id WHERE (rs.first_execution_time >= @history_start_time AND rs.last_execution_time < @history_end_time) OR (rs.first_execution_time <= @history_start_time AND rs.last_execution_time > @history_start_time) OR (rs.first_execution_time <= @history_end_time AND rs.last_execution_time > @history_end_time) GROUP BY p.query_id ), recent AS ( SELECT p.query_id query_id, ROUND(ROUND(CONVERT(FLOAT, SUM(rs.avg_duration * rs.count_executions)) * 0.001, 2), 2) AS total_duration, SUM(rs.count_executions) AS count_executions, COUNT(distinct p.plan_id) AS num_plans FROM sys.query_store_runtime_stats AS rs JOIN sys.query_store_plan AS p ON p.plan_id = rs.plan_id WHERE (rs.first_execution_time >= @recent_start_time AND rs.last_execution_time < @recent_end_time) OR (rs.first_execution_time <= @recent_start_time AND rs.last_execution_time > @recent_start_time) OR (rs.first_execution_time <= @recent_end_time AND rs.last_execution_time > @recent_end_time) GROUP BY p.query_id ) SELECT results.query_id AS query_id, results.query_text AS query_text, results.additional_duration_workload AS additional_duration_workload, results.total_duration_recent AS total_duration_recent, results.total_duration_hist AS total_duration_hist, ISNULL(results.count_executions_recent, 0) AS count_executions_recent, ISNULL(results.count_executions_hist, 0) AS count_executions_hist FROM ( SELECT hist.query_id AS query_id, qt.query_sql_text AS query_text, ROUND(CONVERT(float, recent.total_duration/ recent.count_executions-hist.total_duration/hist.count_executions) *(recent.count_executions), 2) AS additional_duration_workload, ROUND(recent.total_duration, 2) AS total_duration_recent, ROUND(hist.total_duration, 2) AS total_duration_hist, recent.count_executions AS count_executions_recent, hist.count_executions AS count_executions_hist FROM hist JOIN recent ON hist.query_id = recent.query_id JOIN sys.query_store_query AS q ON q.query_id = hist.query_id JOIN sys.query_store_query_text AS qt ON q.query_text_id = qt.query_text_id ) AS results WHERE additional_duration_workload > 0 ORDER BY additional_duration_workload DESC OPTION (MERGE JOIN); |
维护查询性能稳定性
对于执行多次的查询,你可能注意到 SQL Server 使用了会导致不同资源利用率和持续时间的不同计划。 借助查询存储,可以检测到查询性能何时回归,并确定在感兴趣的时间段内的最优计划。 然后你可以对未来的查询执行强制执行此最优计划。
你还可以使用参数(自动参数化或手动参数化)来标识某一查询内不一致的查询性能。 你可以在不同计划中标识出对所有或大多数参数值而言足够快和最佳的计划,并强制执行此计划,为更大范围的用户场景保持可预测的性能。
强制执行查询计划(应用强制策略)
当强制执行某一查询的计划时,SQL Server 尝试在优化器中强制执行该计划。 如果计划强制实施失败,将触发 XEvent,并指示优化器正常优化。
SQL
1 | EXEC sp_query_store_force_plan @query_id = 48, @plan_id = 49; |
在使用 sp_query_store_force_plan 时,你只可以强制执行查询存储记录为该查询计划的那些计划。 换句话说,可用于查询的计划只有那些在查询存储处于活动状态时已用于执行该查询的计划。
备注
Azure Synapse Analytics 不支持在查询存储中强制执行计划。
计划强制支持快进和静态游标
从 SQL Server 2019 (15.x) 和 Azure SQL 数据库(所有部署模型)开始,查询数据存储支持为快进和静态 Transact-SQL 及 API 游标强制执行查询执行计划。 通过 sp_query_store_force_plan 或通过 SQL Server Management Studio 查询存储报表支持强制执行。
删除为查询强制执行的计划
若要再次依靠 SQL Server 查询优化器来计算最佳查询计划,请使用 sp_query_store_unforce_plan 来取消强制执行为查询选定的计划。
SQL
1 | EXEC sp_query_store_unforce_plan @query_id = 48, @plan_id = 49; |
管理查询存储的最佳做法
本文概述了 SQL Server 查询存储的管理及其相关功能。
若要详细了解如何使用查询存储进行配置和管理,请参阅使用查询存储监视性能。
备注
在 SQL Server 2022 (16.x) 中,所有新创建的 SQL Server 数据库默认启用查询存储,以便更好地跟踪性能历史记录、排查查询计划相关问题并启用新的查询处理器功能。
Azure SQL 数据库中的查询存储默认值
本部分介绍 Azure SQL 数据库中的最佳配置默认值,这些默认值旨在确保查询存储以及依赖功能能够可靠运行。 默认配置已针对持续数据收集操作进行优化,即,在 OFF/READ_ONLY 状态下花费最少的时间。 有关所有可用的查询存储选项的详细信息,请参阅 ALTER DATABASE SET 选项 (Transact-SQL)。
展开表
| 配置 | 说明 | 默认 | 注释 |
|---|---|---|---|
| MAX_STORAGE_SIZE_MB | 指定 Query Store 在客户数据库中占用的数据空间的限制 | 100,SQL Server 2019 (15.x) 之前的版本 1000,从 SQL Server 2019 (15.x) 开始 | 对新数据库强制实施 |
| INTERVAL_LENGTH_MINUTES | 定义聚合和持久化查询计划收集运行时统计信息的时段大小。 每个活动查询计划将为此配置定义的时间段包含最多一行 | 60 | 对新数据库强制实施 |
| STALE_QUERY_THRESHOLD_DAYS | 基于时间的清理策略,控制持久化运行时统计信息和非活动查询的保留期 | 30 | 对新数据库和使用以前的默认值 (367) 的数据库强制实施 |
| SIZE_BASED_CLEANUP_MODE | 指定当 Query Store 数据大小接近限制时是否自动清理数据 | AUTO | 对所有数据库强制实施 |
| QUERY_CAPTURE_MODE | 指定是要跟踪所有查询,还是只跟踪一部分查询 | AUTO | 对所有数据库强制实施 |
| DATA_FLUSH_INTERVAL_SECONDS | 指定捕获的运行时统计信息在刷新到磁盘之前,保留在内存中的最大期限 | 900 | 对新数据库强制实施 |
重要
在查询存储的最终激活阶段,系统会在 Azure SQL 数据库中自动应用这些默认值。 启用后,Azure SQL 数据库不会更改客户设置的配置值,除非这些值对主要工作负载或查询存储的可靠运行造成负面影响。
备注
无法在 Azure SQL 数据库的单一数据库和弹性池中禁用查询存储。 执行 ALTER DATABASE [database] SET QUERY_STORE = OFF 将返回警告“'QUERY_STORE=OFF' is not supported in this version of SQL Server.”
如果想要保持使用自定义设置,请结合 Query Store 选项使用 ALTER DATABASE,将配置还原到以前的状态。 请查看查询存储最佳做法,了解如何选择最佳的配置参数。
设置最佳查询存储捕获模式
在 Query Store 中保留最相关数据。 下表描述了每个查询存储捕获模式的典型方案:
展开表
| Query Store 捕获模式 | 场景 |
|---|---|
| 全部 | 对工作负载进行彻底地分析,分析所有查询的形状及其执行频率和其他统计信息。 识别工作负荷中的新查询。 检测是否使用即席查询来识别用户或自动参数化的机会。 注意:这是 SQL Server 2016 (13.x) 和 SQL Server 2017 (14.x) 中的默认捕获模式。 |
| Auto | 关注相关且可操作的查询。 例如,那些定期执行的查询或资源消耗很大的查询。 注意:在 SQL Server 2019 (15.x) 及更高版本中,这是默认捕获模式。 |
| 无 | 你已经捕获了需要在运行时监视的查询集,因此需消除其他查询可能会带来的干扰。 “无”适用于测试和基准测试环境。 “无”也适用于需要提供已配置的 Query Store 配置来监视其应用程序工作负荷的软件供应商。 在使用“无”时应格外小心,因为可能无法跟踪和优化重要的新查询。 避免使用“无”,除非你的特定方案需要使用它。 |
| 自定义 | SQL Server 2019 (15.x) 在 ALTER DATABASE ... SET QUERY_STORE 命令下引入了自定义捕获模式。 虽然“Auto”是默认设置且建议使用,但如果担心查询存储可能会引入开销,数据库管理员可以使用自定义捕获策略进一步优化查询存储捕获行为。 有关详细信息和建议,请参阅本文后面的自定义捕获策略。 有关此语法的详细信息,请参阅 ALTER DATABASE SET 选项。 |
备注
当查询存储捕获模式设置为“全部”、“自动”或“自定义”时,始终捕获游标、存储过程中的查询和本机编译的查询。 若要捕获本机编译的查询,请使用 sys.sp_xtp_control_query_exec_stats 启用每个查询统计信息的收集。
在 Query Store 中保留最相关数据
将查询存储配置为只包含最相关的数据,这样在持续运行的时候对常规工作负载的影响最小,方便进行故障排除。
下表提供最佳实践:
展开表
| 最佳做法 | 设置 |
|---|---|
| 对保留的历史数据进行限制。 | 配置基于时间的策略以激活自动清理功能。 |
| 筛选掉不相关的查询。 | 将“查询存储捕获模式”配置为“自动”。 |
| 达到最大大小时,删除不太相关的查询。 | 激活基于大小的清理策略。 |
自定义捕获策略
启用 CUSTOM 查询存储捕获模式后,可以在新的“查询存储捕获策略设置”下使用其他查询存储配置,以微调特定服务器中的数据收集。
新的自定义设置定义在内部捕获策略时间阈值期间执行的操作。 这是评估配置条件的时间边界,如果所有值为 true,则查询存储可以捕获查询。
查询存储捕获模式指定了查询存储的查询捕获策略。
- All:捕获所有查询。 此选项是 SQL Server 2016 (13.x) 和 SQL Server 2017 (14.x) 中的默认选项。
- Auto:忽略不太频繁的查询以及编译和执行持续时间不长的查询。 执行计数、编译和运行时持续时间的阈值由内部决定。 从 SQL Server 2019 (15.x) 开始,这是默认选项。
- None:查询存储停止捕获新查询。
- Custom:支持额外控件和微调数据收集策略功能。 新的自定义设置定义在内部捕获策略时间阈值期间执行的操作。 这是评估配置条件的时间边界,如果所有值为 true,则查询存储可以捕获查询。
在下列情况下,应考虑为环境优化适当的自定义捕获策略:
 使用最新版本的 SQL Server Management Studio (SSMS)
使用最新版本的 SQL Server Management Studio (SSMS)
若要查看 Management Studio 中的当前设置:
- 在 SQL Server Management Studio 对象资源管理器中,右键单击数据库。
- 选择“属性”。
- 选择查询存储。 在查询存储页面上,验证操作模式(请求)是否为 Read write。
- 将查询存储捕获模式更改为 Custom。
- 注意,查询存储捕获策略下的四个捕获策略字段现已启用并可配置。
自定义捕获策略示例
以下示例将 QUERY_CAPTURE_MODE 设置为 AUTO 并设置自定义捕获模式。 以下每一项都将自定义捕获策略设置为 SQL Server 2022 (16.x) 中的默认值。 考虑调整这些值,以减少捕获的查询数,从而减少查询存储的磁盘占用空间。 建议按小增量逐步更改这些值。
SQL
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | ALTER DATABASE [QueryStoreDB] SET QUERY_STORE = ON ( OPERATION_MODE = READ_WRITE, CLEANUP_POLICY = ( STALE_QUERY_THRESHOLD_DAYS = 90 ), DATA_FLUSH_INTERVAL_SECONDS = 900, MAX_STORAGE_SIZE_MB = 1000, INTERVAL_LENGTH_MINUTES = 60, SIZE_BASED_CLEANUP_MODE = AUTO, QUERY_CAPTURE_MODE = CUSTOM, QUERY_CAPTURE_POLICY = ( STALE_CAPTURE_POLICY_THRESHOLD = 24 HOURS, EXECUTION_COUNT = 30, TOTAL_COMPILE_CPU_TIME_MS = 1000, TOTAL_EXECUTION_CPU_TIME_MS = 100 ) ); |
以下示例查询将更改现有查询存储,以使用自定义捕获策略来替代 EXECUTION_COUNT 和 TOTAL_COMPILE_CPU_TIME_MS 的默认设置。
SQL
1 2 3 4 5 6 7 8 9 | ALTER DATABASE [QueryStoreDB] SET QUERY_STORE = ON ( QUERY_CAPTURE_MODE = CUSTOM, QUERY_CAPTURE_POLICY = ( EXECUTION_COUNT = 100, TOTAL_COMPILE_CPU_TIME_MS = 10000 ) ); |
查询存储最大大小
从 SQL Server 2019 (15.x) 开始,查询存储的默认最大大小值为 1000 MB。 在以前的版本中,默认值为 100 MB。 在具有多个唯一查询计划的忙碌数据库中,增加查询存储的最大大小限制较为合适。 调整捕获策略(见上一节)是限制查询存储的磁盘大小并防止查询存储进入 READ_ONLY 模式的重要考虑因素。 当查询存储收集查询、执行计划和统计信息时,其在数据库中的大小会一直增长,直至达到此限制。 达到此限制后,Query Store 会自动将操作模式更改为 READ_ONLY,并停止收集新数据,这意味着你的性能分析自此不再精确。
- 在 SQL Server 和 Azure SQL 托管实例中,不会严格执行限制
MAX_STORAGE_SIZE_MB。 - 在 Azure SQL 数据库中,允许的最大
MAX_STORAGE_SIZE_MB值为 10,240 MB。
仅当查询存储将数据写入磁盘时才检查存储大小。 此间隔由 DATA_FLUSH_INTERVAL_SECONDS 选项或 Management Studio 查询存储对话框选项“数据刷新间隔”设置。
间隔时间默认值为 900 秒(或 15 分钟)。
如果查询存储已违反存储大小检查之间的
MAX_STORAGE_SIZE_MB限制,则转换为只读模式。如果启用了
1SIZE_BASED_CLEANUP_MODE,则也会触发强制实施
1MAX_STORAGE_SIZE_MB限制的清理机制。
- 清除足够的空间后,查询存储模式将自动切换回 READ_WRITE 模式。
有关详细信息,请参阅 ALTER DATABASE SET OPTION MAX_STORAGE_SIZE_MB。
数据刷新间隔(分钟)
数据刷新间隔定义了收集的运行时统计信息保存到磁盘之前的频率。 在 SQL Server Management Studio 中,该值以分钟为单位,但在 Transact-SQL 中,该值以秒为单位表示。 默认值为 15 分钟(900 秒)。
- 增加数据刷新间隔会降低查询存储存储 I/O 的总体影响,但会导致存储 I/O 工作负载达到高峰,对磁盘利用率的影响较小但更严重。 如果工作负载不生成大量不同的查询和计划或者你能够接受在数据库关闭之前花更长的时间来保留数据,可考虑使用更大的值。
减少数据刷新间隔会减少在关闭、断电或故障转移时丢失的查询存储数据量。 它还可以通过更频繁地写入磁盘,但使用更少的数据来平滑查询存储的 I/O 影响。
备注
本人提供Oracle(OCP、OCM)、MySQL(OCP)、PostgreSQL(PGCA、PGCE、PGCM)等数据库的培训和考证业务,私聊QQ646634621或微信dbaup66,谢谢!



{kind=link}