
合 Oracle利用闪回数据库(flashback)功能修复Failover后的DG环境
Tags: Oracle高可用DGfailover闪回数据库
文章目录[隐藏]
前言部分
导读和注意事项
各位技术爱好者,看完本文后,你可以掌握如下的技能,也可以学到一些其它你所不知道的知识,\~O(∩_∩)O\~:
① Failover后DG环境的恢复方法(重点)
② DG的基本维护操作
③ GC客户端软件的安装
④ 利用GC快速搭建一套DG环境
⑤ Failover和Switchover的区别
⑥ 其它维护操作
本文简介
10月23和24日考完了OCM,感觉过关的法则就是“真题+多练”,练习过10来遍,基本就可以考过了。OCM的考试内容除了GC这块小麦苗没有接触过,其它内容基本都算熟。基本命令熟记于心,不熟的命令可以立马找到官方文档,善用OEM和SQL Developer工具。所以,想快速通过OCM考试的朋友可以私下联系小麦苗,小麦苗会把自己的经验全都教给大家。
好了,废话不多说了。最近小麦苗的DBA宝典微信群里,有朋会友问到了Failover操作后,如何恢复到最初的DG环境。这个问题,小麦苗大概知道利用闪回可以实现,只是没有做过实验,或者曾经做过实验,只是没有记录文档,反正就是年纪大了,想不起来了。好吧,最近就抽个时间把这个实验做一遍。有不对的地方,依然请大家指出。

实验准备
实验环境介绍
实验环境为练习OCM的虚拟机环境:
| 项目 | Source DB | Target DB |
|---|---|---|
| DB 类型 | 单机 | 单机 |
| DB VERSION | 11.2.0.3.0 | 11.2.0.3.0 |
| DB 存储 | FS | FS |
| OS版本及kernel版本 | OEL linux 5.4 32 | OEL linux 5.4 32 |
| DB_NAME | PROD1 | PROD1 |
| ORACLE_SID | PROD1 | SBDB1 |
| ORACLE_HOME | /u01/app/oracle/product/11.2.0/dbhome_1 | /u01/app/oracle/product/11.2.0/db_1 |
| hosts文件 | 10.190.104.111 edsir4p1.us.oracle.com edsir4p1 10.190.104.28 edsir1p8.us.oracle.com edsir1p8 |
实验目标
备库执行FAILOVER后,通过闪回数据库技术重新恢复DG环境,而不用重新搭建DG。
实验过程

利用GC快速搭建DG环境
小麦苗手头的DG环境是在一个主机上,测试多有不便,刚好,最近练习OCM的环境还在,就用练习OCM的环境来做这个实验吧。若已经有DG环境的朋友可以略过该小节内容。
安装GC客户端软件
1、起动GC服务器,首先确保EMREP数据库处于OPEN状态,监听也已经启动,GC服务器启动日志为:/u01/app/gc_inst/em/EMGC_OMS1/sysman/log/emctl.log
cd /u01/app/oracle/Middleware/oms11g/bin
./emctl start oms
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | [oracle@edsir1p8- ~]$ ps -ef|grep pmon oracle 4763 1 0 00:53 ? 00:00:00 ora_pmon_EMREP oracle 11802 11633 0 01:39 pts/2 00:00:00 grep pmon [oracle@edsir1p8- ~]$ cd /u01/app/ gc_inst/ Middleware/ oracle/ oraInventory/ [oracle@edsir1p8- ~]$ cd /u01/app/Middleware/oms11g/bin [oracle@edsir1p8- bin]$ ./emctl start oms Oracle Enterprise Manager 11g Release 1 Grid Control Copyright (c) 1996, 2010 Oracle Corporation. All rights reserved. Starting WebTier... WebTier Successfully Started Starting Oracle Management Server... Oracle Management Server Successfully Started AdminServer Could Not Be Started Oracle Management Server is Up [oracle@edsir1p8- bin]$ more /etc/hosts # Do not remove the following line, or various programs # that require network functionality will fail. 127.0.0.1 localhost.localdomain localhost 10.190.104.28 edsir1p8.us.oracle.com edsir1p8 10.190.104.111 edsir4p1.us.oracle.com edsir4p1 [oracle@edsir1p8- bin]$ ./emctl status oms -details Oracle Enterprise Manager 11g Release 1 Grid Control Copyright (c) 1996, 2010 Oracle Corporation. All rights reserved. Enter Enterprise Manager Root (SYSMAN) Password : Console Server Host : edsir1p8.us.oracle.com HTTP Console Port : 7788 HTTPS Console Port : 7799 HTTP Upload Port : 4889 HTTPS Upload Port : 4900 OMS is not configured with SLB or virtual hostname Agent Upload is locked. OMS Console is locked. Active CA ID: 1 |
2、安装agent
https://10.190.104.28:4900/agent_download/ 从这里下载
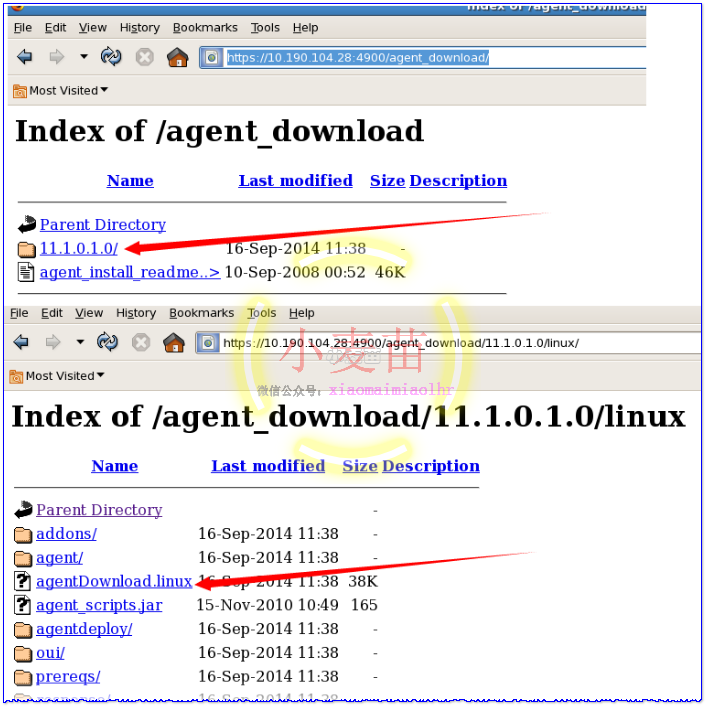
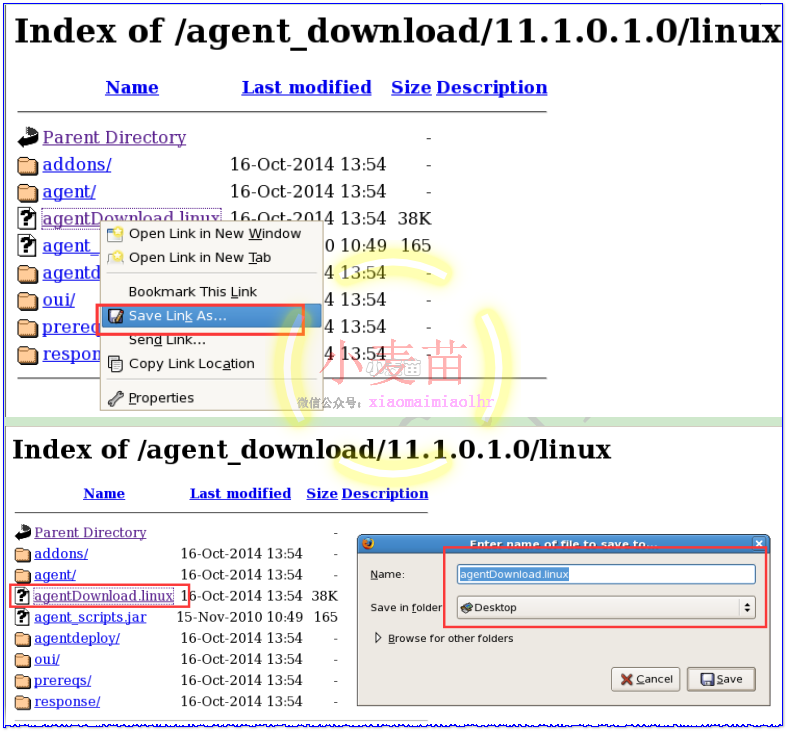
右键保存到桌面。
a、在需要安装agent的机器上mkdir /u01/app/agentbase 创建目录,并将agentDownload.linux文件cp到/u01/app/agentbase目录下,并且赋予可执行权限。
b、在服务端OMS启动的情况下,在客户端执行:
./agentDownload.linux -b /u01/app/agentbase -m edsir1p8.us.oracle.com -r 7799 -y
安装过程中要输入偶数机上OMS的密码
c、安装完成要用root执行:
[root@edsir4p1 \~]## sudo /u01/app/agentbase/agent11g/root.sh
没有root密码要使用sudo执行,注意:一定要执行该脚本,它会设置一些文件的权限(该脚本会把\$AGENT_HOME/bin/nm*的几个文件的所有者修改为root。)。如果不执行,那么搭建DG可能会报错:“ERROR: NMO not setuid-root (Unix-only)”
d、进入/u01/app/agentbase/agent11g/bin
./emctl status agent 检查同步状态
./emctl upload agent 上传同步
./emctl secure agent 重新注册agent,用于安装时密码输错
过程如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 | [oracle@edsir4p1-PROD2 ~]$ mkdir -p /u01/app/agentbase [oracle@edsir4p1-PROD2 ~]$ cd /u01/app/agentbase [oracle@edsir4p1-PROD2 agentbase]$ cp /home/oracle/Desktop/agentDownload.linux . [oracle@edsir4p1-PROD2 agentbase]$ chmod +x agentDownload.linux [oracle@edsir4p1-PROD2 agentbase]$ ll total 40 -rwxr-xr-x 1 oracle oinstall 38525 Nov 6 01:46 agentDownload.linux [oracle@edsir4p1-PROD2 agentbase]$ ./agentDownload.linux agentDownload.linux invoked on Mon Nov 6 01:46:55 UTC 2017 with Arguments "" agentDownload.linux: Invalid Invocation Usage: agentDownload.linux -b[cdhimnoprtuvxyNR] b - Base installation location for Agent Oracle home d - Do NOT initiate automatic target discovery h - Usage (this message) i - Inventory pointer location file l - To specify as local host (pass -local to runInstaller) m - Management Service host name for downloading the Management Agent software n - Cluster name o - Old Oracle Home location during Upgrade p - Static port list file r - Port for connecting to the Management Service host t - Do NOT start the Agent u - Upgrade v - Inventory directory location x - Debug output c - CLUSTER_NODES N - Do NOT prompt for Agent Registration Password R - To use virtual hostname(ORACLE_HOSTNAME) for this installation. If this is being used along with more than one cluster nodes through -c option, then -l option also needs to be passed. y - Decline Security Updates. [oracle@edsir4p1-PROD2 agentbase]$ ./agentDownload.linux -b /u01/app/agentbase -m edsir1p8.us.oracle.com -r 7799 -y agentDownload.linux invoked on Mon Nov 6 01:49:01 UTC 2017 with Arguments "-b /u01/app/agentbase -m edsir1p8.us.oracle.com -r 7799 -y" Platform=Linux.i686, OS=linux GetPlatform:returned=0, and os is set to: linux, platform=Linux.i686 Creating /u01/app/agentbase/agentDownload11.1.0.1.0Oui ... LogFile for this Download can be found at: "/u01/app/agentbase/agentDownload11.1.0.1.0Oui/agentDownload.linux110617014901.log" Running on Selected Platform: Linux.i686 Installer location: /u01/app/agentbase/agentDownload11.1.0.1.0Oui Downloading Agent install response file ... Downloading Agent install response file ... Executing wget_get_file 。。。。。。。。。。省略部分。。。。。。 Finished Downloading agent_download.rsp with Status=0 Response file check Complete - Success Checking the writable permission for baseDir - passed Provide the Agent Registration password so that the Management Agent can communicate with Secure Management Service. Note: You may proceed with the installation without supplying the password; however, Management Agent can be secured manually after the installation. If Oracle Management Service is not secured, agent will not be secured, so continue by pressing Enter Key. Enter Agent Registration Password: <<<<=输入密码 Downloading Oracle Installer ... Executing wget_get_file https://edsir1p8.us.oracle.com:7799/agent_download/11.1.0.1.0/linux/oui/oui_linux.jar using the url https://edsir1p8.us.oracle.com:7799/agent_download/11.1.0.1.0/ to access OMS 。。。。。。。。。。省略部分。。。。。。 Configuration assistant "Agent Configuration Assistant" Succeeded AgentPlugIn:agent configuration finished with status = true Running Configuration assistant "Agent Add-on Plug-in" Configuration assistant "Agent Add-on Plug-in" Succeeded Querying Agent status: Agent is running Removing the copied stuff..... Removed: /u01/app/agentbase/agentDownload11.1.0.1.0Oui/oui_linux.jar Removed: /u01/app/agentbase/agentDownload11.1.0.1.0Oui/agent_download.rsp Removed:/u01/app/agentbase/agentDownload11.1.0.1.0Oui/Disk1 Log name of installation can be found at: "/u01/app/agentbase/agentDownload.linux110617014901.log" /u01/app/agentbase/agent11g/root.sh needs to be executed by root to complete this installation. [oracle@edsir4p1-PROD2 agentbase]$ sudo /u01/app/agentbase/agent11g/root.sh [oracle@edsir4p1-PROD2 agentbase]$ ll total 80 drwxr-xr-x 40 oracle oinstall 4096 Nov 6 01:53 agent11g drwxr-xr-x 2 oracle oinstall 4096 Nov 6 01:53 agentDownload11.1.0.1.0Oui -rwxr-xr-x 1 oracle oinstall 38525 Nov 6 01:46 agentDownload.linux -rw-r--r-- 1 oracle oinstall 78 Nov 6 01:46 agentDownload.linux110617014655.log -rw-r--r-- 1 oracle oinstall 24908 Nov 6 01:53 agentDownload.linux110617014901.log [oracle@edsir4p1-PROD2 agentbase]$ cd agent11g/bin/ [oracle@edsir4p1-PROD2 bin]$ ./emctl status agent Oracle Enterprise Manager 11g Release 1 Grid Control 11.1.0.1.0 Copyright (c) 1996, 2010 Oracle Corporation. All rights reserved. --------------------------------------------------------------- Agent Version : 11.1.0.1.0 OMS Version : 11.1.0.1.0 Protocol Version : 11.1.0.0.0 Agent Home : /u01/app/agentbase/agent11g Agent binaries : /u01/app/agentbase/agent11g Agent Process ID : 26954 Parent Process ID : 26914 Agent URL : https://edsir4p1.us.oracle.com:3872/emd/main/ Repository URL : https://edsir1p8.us.oracle.com:4900/em/upload Started at : 2017-11-06 01:53:15 Started by user : oracle Last Reload : 2017-11-06 01:53:15 Last successful upload : 2017-11-06 01:55:13 Total Megabytes of XML files uploaded so far : 17.86 Number of XML files pending upload : 0 Size of XML files pending upload(MB) : 0.00 Available disk space on upload filesystem : 83.54% Last successful heartbeat to OMS : 2017-11-06 01:57:20 --------------------------------------------------------------- Agent is Running and Ready [oracle@edsir4p1-PROD2 bin]$ |
使用GC快速搭建物理备库
从浏览器打开https://10.190.104.28:7799/em/,使用sysman用户进行登录。
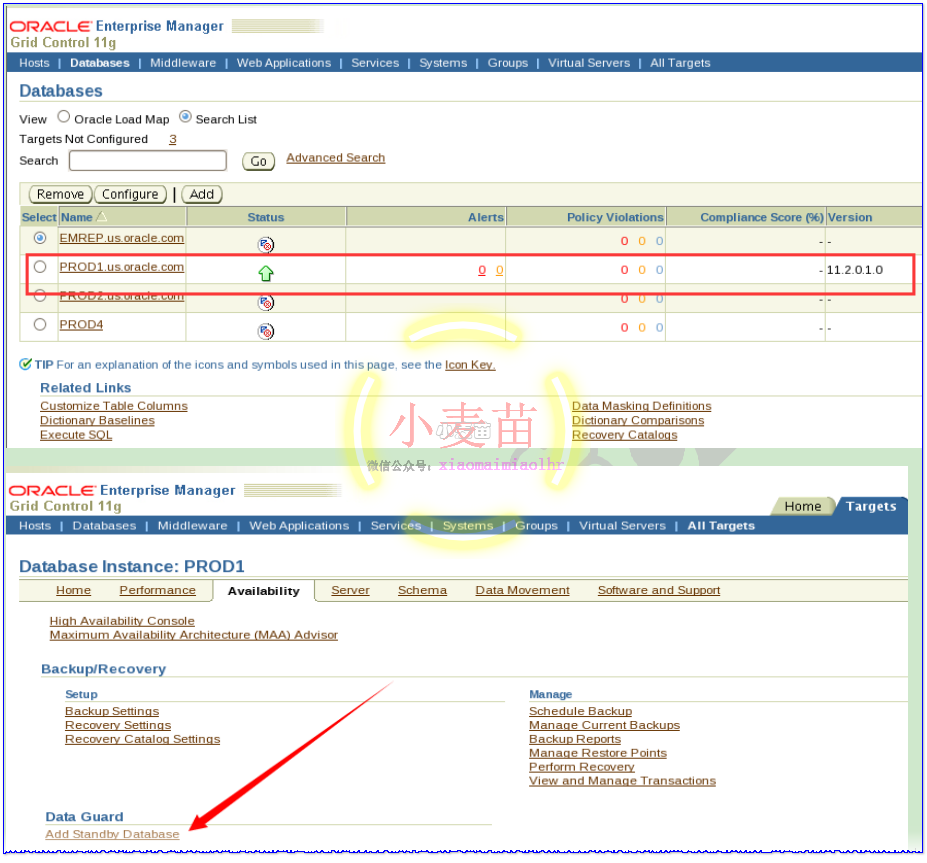
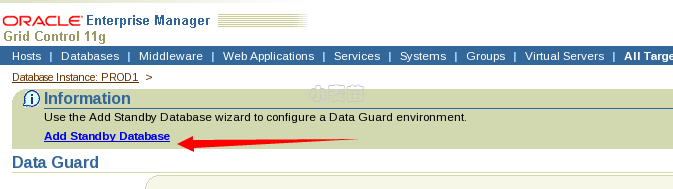
使用sys用户登录PROD1数据库。
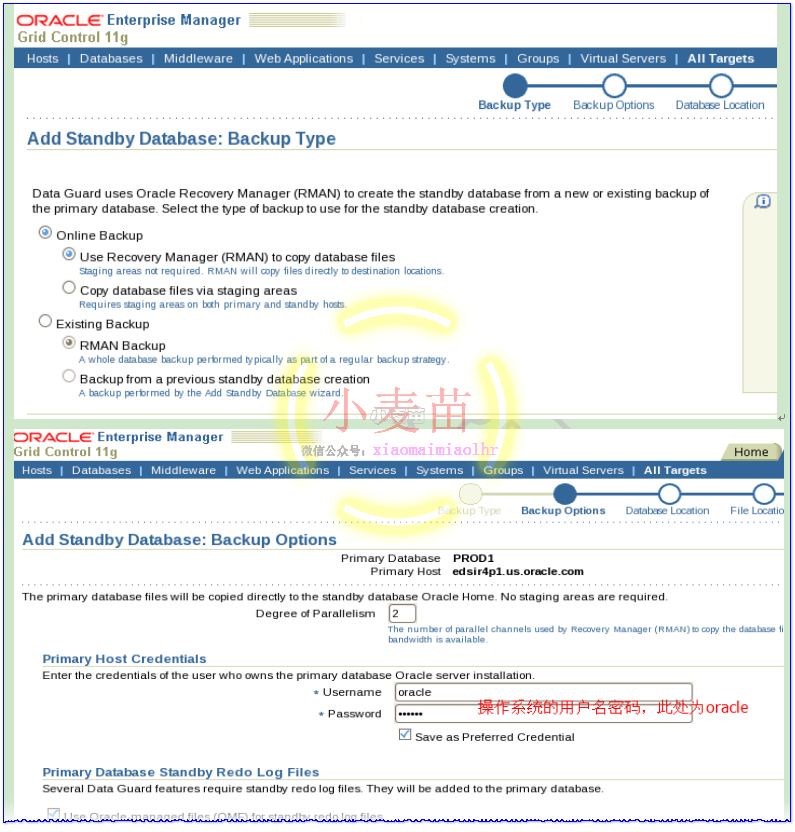
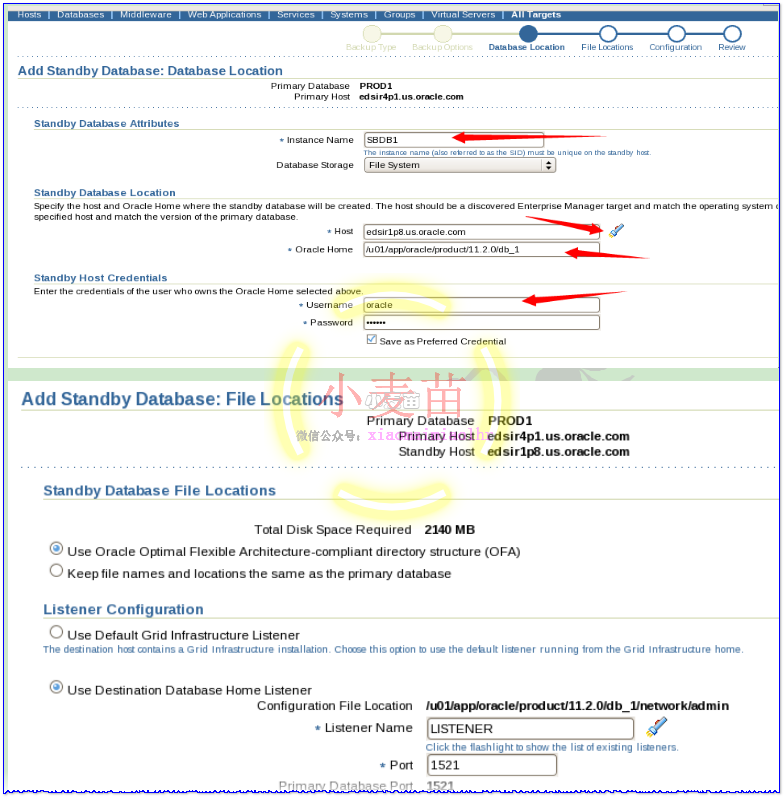
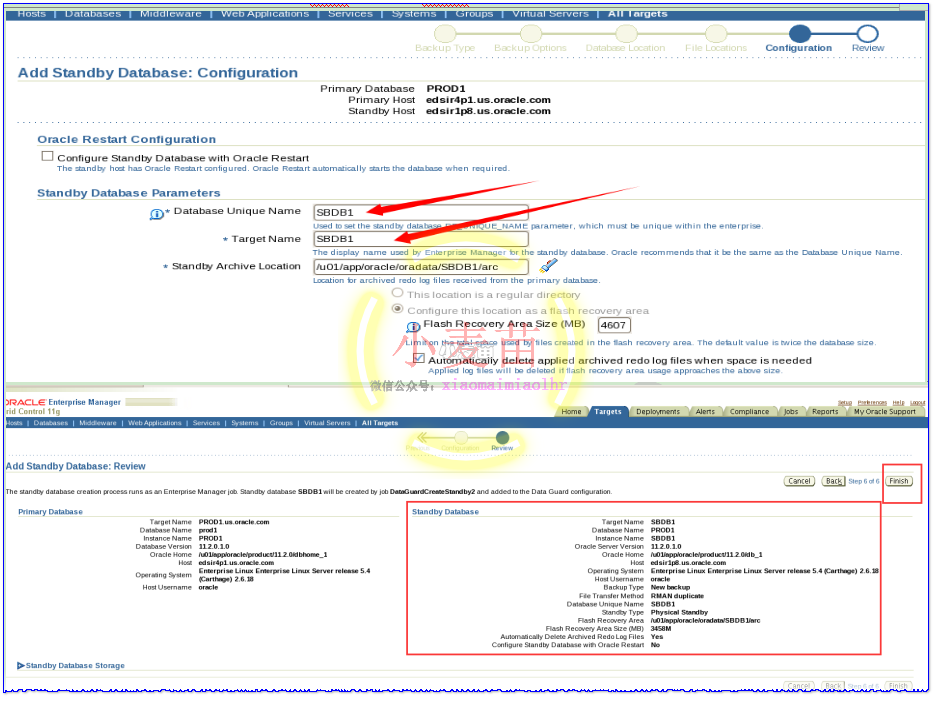
等待大约10分钟即可自动完成DG的搭建和配置工作。期间,可以查看主库和备库的告警日志以及数据文件夹的大小来预估搭建完成时间。
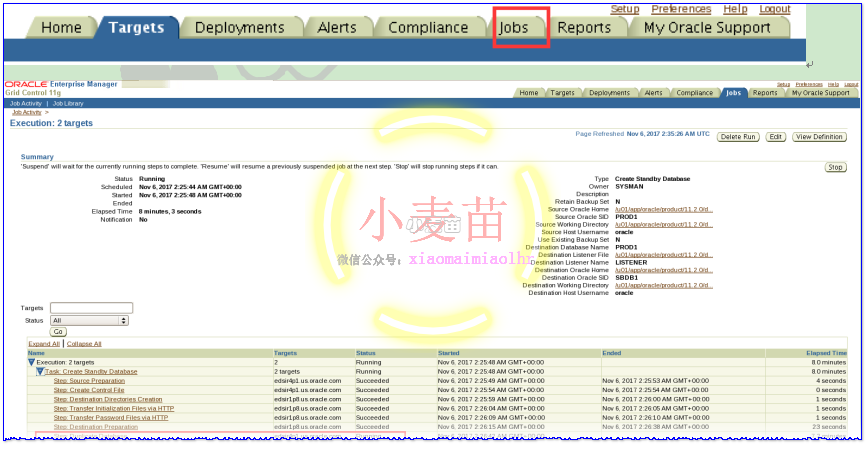
创建完成后:
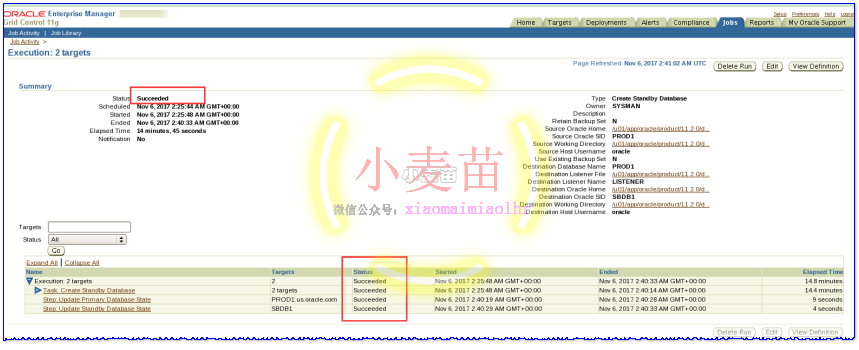
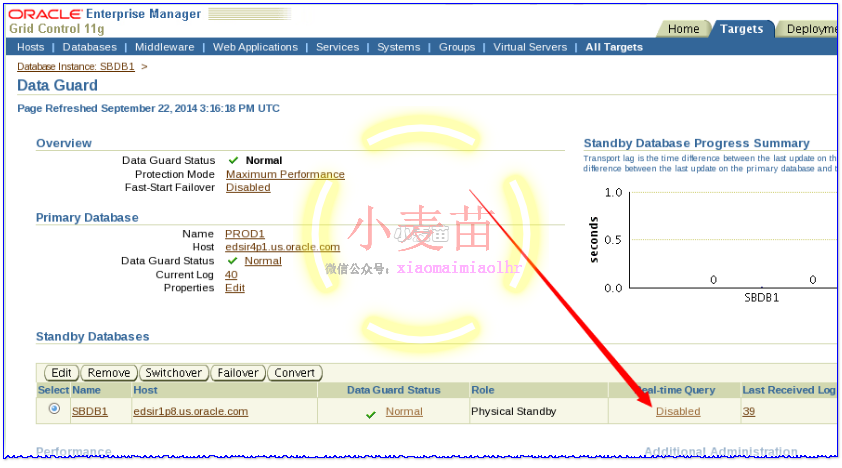
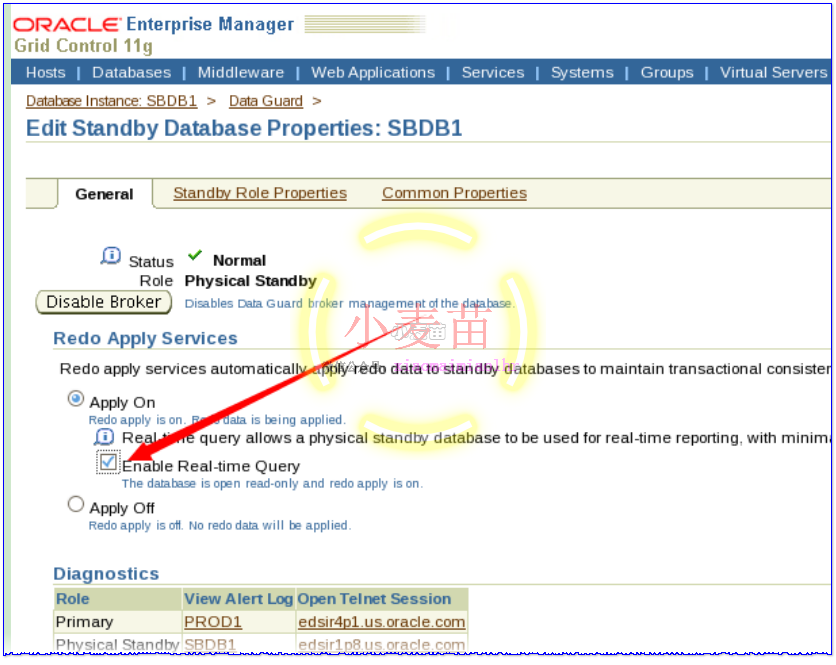
启用实时应用
开启主备库闪回
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | 主库: SQL> select name, open_mode, database_role, flashback_on from v$database; NAME OPEN_MODE DATABASE_ROLE FLASHBACK_ON --------- -------------------- ---------------- ------------------ PROD1 READ WRITE PRIMARY NO SQL> select INSTANCE_NAME,INSTANCE_ROLE from v$instance; INSTANCE_NAME INSTANCE_ROLE ---------------- ------------------ PROD1 PRIMARY_INSTANCE 备库: SQL> select name, open_mode, database_role, flashback_on from v$database; NAME OPEN_MODE DATABASE_ROLE FLASHBACK_ON --------- -------------------- ---------------- ------------------ PROD1 READ ONLY WITH APPLY PHYSICAL STANDBY NO SQL> select INSTANCE_NAME,INSTANCE_ROLE from v$instance; INSTANCE_NAME INSTANCE_ROLE ---------------- ------------------ SBDB1 PRIMARY_INSTANCE 主库开启闪回: SQL> alter database flashback on; Database altered. SQL> select name, open_mode, database_role, flashback_on from v$database; NAME OPEN_MODE DATABASE_ROLE FLASHBACK_ON --------- -------------------- ---------------- ------------------ PROD1 READ WRITE PRIMARY YES SQL> select oldest_flashback_scn, to_char(oldest_flashback_time,'yyyy-mm-dd HH24:mi:ss') oldest_flashback_time from v$flashback_database_log; OLDEST_FLASHBACK_SCN OLDEST_FLASHBACK_TI -------------------- ------------------- 867005 2017-11-06 02:55:59 SQL> show parameter flashback NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ db_flashback_retention_target integer 1440 ====>参数db_flashback_retention_target控制闪回时间范围,数字单位是分钟,默认为1天。这个数字决定了闪回的时间范围,如果设置更长的时间,对应的闪回日志文件大小就会比较大一些。 |
告警日志:
1 2 3 4 5 6 7 8 9 | Mon Nov 06 02:55:55 2017 alter database flashback on Starting background process RVWR Mon Nov 06 02:55:56 2017 RVWR started with pid=37, OS id=1096 Allocated 3981204 bytes in shared pool for flashback generation buffer Flashback Database Enabled at SCN 867006 Completed: alter database flashback on |
此时,备库并没有开启闪回,需要在备库上手动开启闪回:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | SQL> alter database flashback on; alter database flashback on * ERROR at line 1: ORA-01153: an incompatible media recovery is active SQL> recover managed standby database cancel; Media recovery complete. SQL> alter database flashback on; Database altered. SQL> select name, open_mode, database_role, flashback_on from v$database; NAME OPEN_MODE DATABASE_ROLE FLASHBACK_ON --------- -------------------- ---------------- ------------------ PROD1 READ ONLY PHYSICAL STANDBY YES SQL> alter database recover managed standby database using current logfile disconnect from session; Database altered. |
实验1
实验1、PROD1意外宕机,SBDB1执行Failover操作变为主库;然后将PROD1利用闪回数据库功能闪回到SBDB1变为主库的SCN时间点,然后将PROD1转换为备库,最后利用switchover转换为最初的环境。\<===PROD1需要开启闪回
Failover操作
切换之前确保监听使用静态监听、fal_client、fal_server、log_archive_dest_1和log_archive_dest_2参数已正确配置。
主库操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | SYS@PROD1> select dbid,name,current_scn,protection_mode,protection_level,database_role,force_logging,open_mode,switchover_status from v$database; DBID NAME CURRENT_SCN PROTECTION_MODE PROTECTION_LEVEL DATABASE_ROLE FOR OPEN_MODE SWITCHOVER_STATUS ---------- ---------- ----------- -------------------- -------------------- ---------------- --- -------------------- -------------------- 2177200393 PROD1 868787 MAXIMUM PERFORMANCE MAXIMUM PERFORMANCE PRIMARY YES READ WRITE TO STANDBY SYS@PROD1> create table test_bylhr as select * from dba_objects; Table created. SYS@PROD1> insert into test_bylhr select * from test_bylhr; 72459 rows created. SYS@PROD1> commit; Commit complete. SYS@PROD1> select count(1) from test_bylhr; COUNT(1) ---------- 144918 SYS@PROD1> shutdown abort ORACLE instance shut down. |
备库操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | SYS@SBDB1> select count(1) from test_bylhr; COUNT(1) ---------- 144918 SYS@SBDB1> alter database recover managed standby database cancel; Database altered. SYS@SBDB1> alter database recover managed standby database finish; Database altered. SYS@SBDB1> set line 9999 SYS@SBDB1> select name, LOG_MODE, OPEN_MODE, database_role, SWITCHOVER_STATUS, db_unique_name from v$database; NAME LOG_MODE OPEN_MODE DATABASE_ROLE SWITCHOVER_STATUS DB_UNIQUE_NAME --------- ------------ -------------------- ---------------- -------------------- ------------------------------ PROD1 ARCHIVELOG READ ONLY PHYSICAL STANDBY SESSIONS ACTIVE SBDB1 SYS@SBDB1> alter database commit to switchover to primary with session shutdown; Database altered. SYS@SBDB1> select name, LOG_MODE, OPEN_MODE, database_role, SWITCHOVER_STATUS, db_unique_name from v$database; NAME LOG_MODE OPEN_MODE DATABASE_ROLE SWITCHOVER_STATUS DB_UNIQUE_NAME --------- ------------ -------------------- ---------------- -------------------- ------------------------------ PROD1 ARCHIVELOG MOUNTED PRIMARY NOT ALLOWED SBDB1 SYS@SBDB1> alter database open; Database altered. |
Primary重新加入
Failover后的Primary数据库,实际上已经失去了和DG的关联,如果Primary故障严重,是难以保障对应的归档数据可以顺利传输的。如果希望Primary重新回到DG环境,关键就是恢复的时间点。要求Primary回到Standby切换角色的那个时间点,理论上就可以“延续”操作。
查询原备库变为新主库的SCN
在原备库端,查看v\$database视图,可以看到这个库成为primary的具体时间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | SYS@SBDB1> select STANDBY_BECAME_PRIMARY_SCN from v$database; STANDBY_BECAME_PRIMARY_SCN -------------------------- 869428 SYS@SBDB1> create table test_bylhr2 as select * from dba_objects where rownum<=1000; Table created. SYS@SBDB1> alter system switch logfile; System altered. SYS@SBDB1> select count(1) from test_bylhr2; COUNT(1) ---------- 1000 SYS@SBDB1> select dbms_flashback.get_system_change_number from dual; GET_SYSTEM_CHANGE_NUMBER ------------------------ 869833 |
原主库执行闪回操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | SYS@PROD1> startup mount ORACLE instance started. Total System Global Area 313860096 bytes Fixed Size 1336232 bytes Variable Size 247467096 bytes Database Buffers 58720256 bytes Redo Buffers 6336512 bytes Database mounted. SYS@PROD1> flashback database to scn 869428; Flashback complete. SYS@PROD1> select dbid,name,current_scn,protection_mode,protection_level,database_role,force_logging,open_mode,switchover_status from v$database; DBID NAME CURRENT_SCN PROTECTION_MODE PROTECTION_LEVEL DATABASE_ROLE FOR OPEN_MODE SWITCHOVER_STATUS ---------- ---------- ----------- -------------------- -------------------- ---------------- --- -------------------- -------------------- 2177200393 PROD1 0 MAXIMUM PERFORMANCE UNPROTECTED PRIMARY YES MOUNTED NOT ALLOWED |
注意:重新加入的原Primary是不能恢复角色的,而是只能先成为Standby角色。应用后续的日志达到同步。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | SYS@PROD1> alter database convert to physical standby; Database altered. SYS@PROD1> startup force; ORACLE instance started. Total System Global Area 313860096 bytes Fixed Size 1336232 bytes Variable Size 247467096 bytes Database Buffers 58720256 bytes Redo Buffers 6336512 bytes Database mounted. Database opened. SYS@PROD1> select dbid,name,current_scn,protection_mode,protection_level,database_role,force_logging,open_mode,switchover_status from v$database; DBID NAME CURRENT_SCN PROTECTION_MODE PROTECTION_LEVEL DATABASE_ROLE FOR OPEN_MODE SWITCHOVER_STATUS ---------- ---------- ----------- -------------------- -------------------- ---------------- --- -------------------- -------------------- 2177200393 PROD1 869428 MAXIMUM PERFORMANCE MAXIMUM PERFORMANCE PHYSICAL STANDBY YES READ ONLY TO PRIMARY SYS@PROD1> alter database recover managed standby database using current logfile disconnect from session; Database altered. SYS@PROD1> select count(1) from test_bylhr2; COUNT(1) ---------- 1000 |
Oracle DG在发生Failover之后,当主库解决问题,是不可以直接回到DG环境的。这个过程往往需要一些辅助组建的配合。如RMAN、Flashback,都可以简化重回DG的过程时间。
注意:如果原主库查询不到test_bylhr2表的数据,则需要仔细检查监听使用静态监听、fal_client、fal_server、log_archive_dest_1和log_archive_dest_2参数已正确配置。
执行switchover切换成初始环境
新主库:
