合 如何使用AWR报告来诊断数据库性能问题 (Doc ID 1523048.1)
- Time Model Statistics
- Time Model Statistics几个特别有用的时间指标:
- Foreground Wait Class
- Foreground Wait Events
- Background Wait Events
- Operating System Statistics
- Service Statistics
- Service Wait Class Stats
- User I/O Total Wts : 对应该服务名下用户I/O类等待的总的次数
- SQL ordered by Elapsed Time
- SQL ordered by CPU Time
- SQL ordered by Reads
- SQL ordered by Physical Reads (UnOptimized)
- SQL ordered by Executions
- SQL ordered by Parse Calls
- SQL ordered by Version Count
- Other Instance Activity Stats
- Instance Activity Stats - Absolute Values
- Tablespace IO Stats
- File IO Stats
- Buffer Pool Statistics
- Checkpoint Activity
- Instance Recovery Stats
- Buffer Pool Advisory
- PGA Aggr Summary
- PGA Aggr Target Histogram
- Shared Pool Advisory
- SGA Target Advisory
- Streams Pool Advisory
- Buffer Wait Statistics
- Enqueue Activity
- Undo Segment Summary
- Undo Extent有三种状态 active 、unexpired 、expired
- Latch Activity
- Latch Sleep Breakdown
- Mutex Sleep Summary
- Segments by Logical Reads
- Segments by Physical Reads
- Segments by Physical Read Requests
- Dictionary Cache Stats
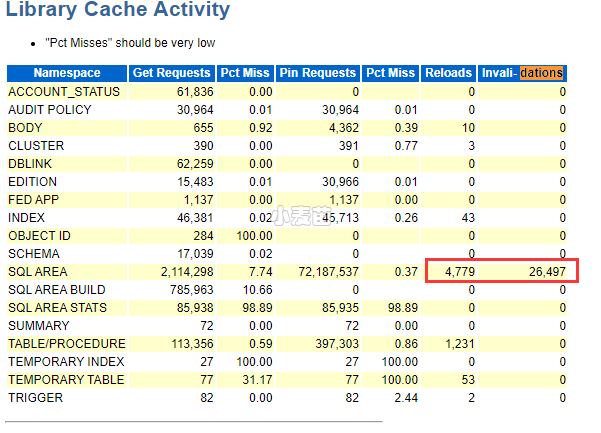
- Library Cache Activity
- SGA Memory Summary
- SGA breakdown difference
【性能调优】Oracle AWR报告指标全解析
原文:https://mp.weixin.qq.com/s/O3R4kcbO7J8LQxRQhIWgWw
1、报告总结
WORKLOAD REPOSITORY report for
| DB Name | DB Id | Instance | Inst num | Startup Time | Release | RAC |
|---|---|---|---|---|---|---|
| CUFS | 3961207481 | cufs | 1 | 24-Aug-19 21:08 | 11.2.0.4.0 | NO |
| Host Name | Platform | CPUs | Cores | Sockets | Memory (GB) |
|---|---|---|---|---|---|
| database | Linux x86 64-bit | 16 | 16 | 4 | 31.48 |
| Snap Id | Snap Time | Sessions | Cursors/Session | |
|---|---|---|---|---|
| Begin Snap: | 9512 | 04-Dec-19 10:00:20 | 85 | 9.3 |
| End Snap: | 9513 | 04-Dec-19 11:00:28 | 80 | 3.4 |
| Elapsed: | 60.14 (mins) | |||
| DB Time: | 64.77 (mins) |
Elapsed为该AWR性能报告的时间跨度(自然时间的跨度,例如前一个快照snapshot是9点生成的,后一个快照snapshot是11点生成的,
则若使用@?/rdbms/admin/awrrpt 脚本中指定这2个快照的话,那么其elapsed = (11-9)=2 个小时)
一个AWR性能报告至少需要2个AWR snapshot性能快照才能生成 ( 这2个快照时间实例不能重启过,否则指定这2个快照生成AWR性能报告会报错),
DB TIME= 所有前台session花费在database调用上的总和时间:
注意是前台进程foreground sessions
包括CPU时间、IO Time、和其他一系列非空闲等待时间
DB TIME 不等于 响应时间,DB TIME高了未必响应慢,DB TIME低了未必响应快
DB Time描绘了数据库总体负载,但要和elapsed time结合其来。
Average Active Session AAS= DB time/Elapsed Time
DB Time =60min,Elapsed Time =60min AAS=60/60=1 负载一般
DB Time= 1min,Elapsed Time= 60min AAS= 1/60 负载很轻
DB Time= 60000min,Elapsed Time=60min AAS=1000 系统hang住
DB TIME= DB CPU + Non-Idle Wait + Wait on CPU queue
如果仅有2个逻辑CPU,而2个session在60分钟都没等待事件,一直跑在CPU上,那么:
DB CPU=260mins , DB Time =260 +0 +0 =120
AAS = 120/60=2 正好等于OS load 2。
如果有3个session都100%仅消耗CPU,那么总有一个要wait on queue
DB CPU =2* 60mins ,wait on CPU queue=60mins
AAS= (120+ 60)/60=3 主机load 亦为3,
此时vmstat 看waiting for run time
1-1 内存参数大小
Cache Sizes
| Begin | End | |||
|---|---|---|---|---|
| Buffer Cache: | 2,880M | 2,880M | Std Block Size: | 8K |
| Shared Pool Size: | 4,782M | 4,796M | Log Buffer: | 4,356K |
1-2 Load Profile
Load Profile
| Per Second | Per Transaction | Per Exec | Per Call | |
|---|---|---|---|---|
| DB Time(s): | 1.1 | 0.0 | 0.00 | 0.00 |
| DB CPU(s): | 1.1 | 0.0 | 0.00 | 0.00 |
| Redo size (bytes): | 35,814.6 | 140.3 | ||
| Logical read (blocks): | 22,708.3 | 88.9 | ||
| Block changes: | 230.3 | 0.9 | ||
| Physical read (blocks): | 395.7 | 1.6 | ||
| Physical write (blocks): | 4.6 | 0.0 | ||
| Read IO requests: | 8.7 | 0.0 | ||
| Write IO requests: | 2.3 | 0.0 | ||
| Read IO (MB): | 3.1 | 0.0 | ||
| Write IO (MB): | 0.0 | 0.0 | ||
| User calls: | 2,795.2 | 11.0 | ||
| Parses (SQL): | 635.8 | 2.5 | ||
| Hard parses (SQL): | 20.9 | 0.1 | ||
| SQL Work Area (MB): | 2.7 | 0.0 | ||
| Logons: | 0.1 | 0.0 | ||
| Executes (SQL): | 641.8 | 2.5 | ||
| Rollbacks: | 252.3 | 1.0 | ||
| Transactions: | 255.3 |
指标含义
redo size单位bytes,redosize可以用来估量update/insert/delete的频率,大的redo size往往对lgwr写日志,和arch归档造成I/O压力,
Per Transaction可以用来分辨是大量小事务,还是少量大事务。如上例每秒redo 约1MB,每个事务800 字节,符合OLTP特征
Logical Read 单位(次数*块数),逻辑读耗CPU,主频和CPU核数都很重要,逻辑读高则DB CPU往往高,也往往可以看到latch: cache buffer chains等待。
Block changes 单位(次数*块数),描绘数据变化频率
Physical Read 单位(次数*块数),物理读消耗IO读,体现在IOPS和吞吐量等不同纬度上;但减少物理读可能意味着消耗更多CPU。
好的存储 每秒物理读能力达到几GB,例如Exadata。这个physical read包含了physical reads cache和physical reads direct
Physical writes 单位(次数*块数),主要是DBWR写datafile,也有direct path write。dbwr长期写出慢会导致定期log file switch(checkpoint no complete) 检查点无法完成的前台等待。 这个physical write 包含了physical writes direct +physical writes from cache
User Calls 单位次数,用户调用数,more details from internal
Parses 解析次数,包括软解析+硬解析,软解析优化得不好,则夸张地说几乎等于每秒SQL执行次数。即执行解析比1:1,而我们希望的是解析一次到处运行
Hard Parses 万恶之源:Cursor pin s on X, library cache: mutex X , latch: row cache objects /shared pool……………..。硬解析最好少于每秒20次
W/A MB processed 单位MB W/A workarea workarea中处理的数据数量,结合 In-memory Sort%
Logons 登陆次数, 结合AUDIT审计数据一起看。
Executes 执行次数,反应执行频率
Rollback 回滚次数,反应回滚频率,但是这个指标不太精确,
Transactions 每秒事务数,是数据库层的TPS,可以看做压力测试或比对性能时的一个指标,孤立看无意义
% Blocks changed per Read 每次逻辑读导致数据块变化的比率;如果’redo size’, ‘block changes’ ‘pct of blocks changed per read’三个指标都很高,则说明系统正执行大量insert/update/delete;pct of blocks changed per read = (block changes ) /( logical reads)
Recursive Call % 递归调用的比率;Recursive Call% = (recursive calls)/(user calls)
Rollback per transaction % 事务回滚比率。Rollback per transaction %= (rollback)/(transactions)
Rows per Sort平均每次排序涉及到的行数;Rows per Sort=(sorts(rows) ) / ( sorts(disk) + sorts(memory))
注意这些Load Profile负载指标在本环节提供了2个维度per second和per transaction。
per Second: 主要是把快照内的时间值除以快照时间的秒数,例如在A快照中V$SYSSTAT视图反应 table scans (long tables) 这个指标是 100 ,
在B快照中V$SYSSTAT视图反应 table scans (long tables) 这个指标是 3700, 而A快照和B快照之间间隔了一个小时3600秒,则对于table scans (long tables) per second 就是 ( 3700- 100) /3600=1。
per transaction : 基于事务的维度,与per second相比是把除数从时间的秒数改为了该段时间内的事务数。这个维度的很大用户是用来识别应用特性的变化
若2个AWR性能报告中该维度指标 出现了大幅变化,例如 redo size从本来per transaction 1k变化为 10k per transaction,则说明SQL业务逻辑肯定发生了某些变化。
注意AWR中的这些指标 并不仅仅用来孤立地了解 Oracle数据库负载情况, 实施调优工作。对于 故障诊断 例如HANG、Crash等, 完全可以通过对比问题时段的性能报告和常规时间来对比,通过各项指标的对比往往可以找出 病灶所在。
1-3 Instance Efficiency Percentages (Target 100%
Instance Efficiency Percentages (Target 100%)
| Buffer Nowait %: | 100.00 | Redo NoWait %: | 100.00 |
|---|---|---|---|
| Buffer Hit %: | 100.00 | In-memory Sort %: | 100.00 |
| Library Hit %: | 90.16 | Soft Parse %: | 96.72 |
| Execute to Parse %: | 0.93 | Latch Hit %: | 99.94 |
| Parse CPU to Parse Elapsd %: | 75.79 | % Non-Parse CPU: | 87.28 |
上述所有指标的目标均为100%,越大越好
80%以上 %Non-Parse CPU
90%以上 Buffer Hit%, In-memory Sort%, Soft Parse%
95%以上 Library Hit%, Redo Nowait%, Buffer Nowait%
98%以上 Latch Hit%
1、Buffer Nowait % session申请一个buffer(兼容模式)不等待的次数比例。需要访问buffer时立即可以访问的比率,
1 | 2、buffer HIT%: 高速缓存命中率,反应物理读和缓存命中间的纠结,但这个指标即便99% 也不能说明物理读等待少了 |
不合理的db_cache_size,或者是SGA自动管理ASMM /Memory自动管理AMM下都可能因为db_cache_size过小引起大量的db file sequential /scattered read等待事件;
此外与 buffer HIT%相关的指标值得关注的还有 table scans(long tables) 大表扫描这个统计项目、此外相关的栏目还有Buffer Pool Statistics 、Buffer Pool Advisory等
3、Redo nowait%: session在生成redo entry时不用等待的比例,redo相关的资源争用例如redo space request争用可能造成生成redo时需求等待。此项数据来源于v$sysstat中的(redo log space requests/redo entries)。一般来说10g以后不太用关注log_buffer参数的大小,需要关注是否有十分频繁的 log switch ;过小的redo logfile size 如果配合较大的SGA和频繁的commit提交都可能造成该问题。考虑增到redo logfile 的尺寸 : 1-2G 每个,10-15组都是合适的。同时考虑优化redo logfile和datafile 的I/O。
4、In-memory Sort%:这个指标因为它不计算workarea中所有的操作类型,纯粹在内存中完成的排序比例。
5、Library Hit%: library cache命中率,申请一个library cache object例如一个SQL cursor时,其已经在library cache中的比例。合理值:>95% ,ns
6、Soft Parse: 软解析比例,经典指标,合理值>95%
Soft Parse %是AWR中另一个重要的解析指标,该指标反应了快照时间内软解析次数和总解析次数 (soft+hard 软解析次数+硬解析次数)的比值,若该指标很低,那么说明了可能存在剧烈的hard parse硬解析,大量的硬解析会消耗更多的CPU时间片并产生解析争用(此时可以考虑使用cursor_sharing=FORCE);
理论上我们总是希望 Soft Parse % 接近于100%, 但并不是说100%的软解析就是最理想的解析状态,通过设置 session_cached_cursors参数和反复重用游标我们可以让解析来的更轻量级,即通俗所说的利用会话缓存游标实现的软软解析(soft soft parse)。
7、Execute to Parse%指标反映了执行解析比其公式为 1-(parse/execute) , 目标为100% 及接近于只执行而不解析。在oracle中解析往往是执行的先提工作,但是通过游标共享可以解析一次执行多次,
执行解析可能分成多种场景:
hard coding => 代码硬解析一次,执行一次,理论上其执行解析比为 1:1 ,则理论上Execute to Parse =0 极差,且soft parse比例也为0%
绑定变量但是仍软解析=》软解析一次,执行一次 ,这种情况虽然比前一种好 但是执行解析比(这里的parse,包含了软解析和硬解析)仍是1:1, 理论上Execute to Parse =0 极差,但是soft parse比例可能很高
使用静态SQL、动态绑定、session_cached_cursor、open cursors等技术实现的解析一次,执行多次,执行解析比为N:1,则Execute to Parse= 1- (1/N) 执行次数越多Execute to Parse越接近100%,这种是我们在OLTP环境中希望看到的。
通俗地说 soft parse% 反映了软解析率, 而软解析在oracle中仍是较昂贵的操作, 我们希望的是解析1次执行N次,如果每次执行均需要软解析,那么虽然soft parse%=100% 但是parse time仍可能是消耗DB TIME的大头。
Execute to Parse反映了执行解析比,Execute to Parse和soft parse% 都很低那么说明确实没有绑定变量,而如果 soft parse%接近99%而Execute to Parse 不足90% 则说明没有执行解析比低,需要通过静态SQL、动态绑定、session_cached_cursor、open cursors等技术减少软解析。
8、Latch Hit%: willing-to-wait latch闩申请不要等待的比例。
9、Parse CPU To Parse Elapsd:该指标反映了快照内解析CPU时间和总的解析时间的比值(Parse CPU Time/ Parse Elapsed Time);若该指标水平很低,那么说明在整个解析过程中 实际在CPU上运算的时间是很短的,而主要的解析时间都耗费在各种其他非空闲的等待事件上了(如latch:shared pool,row cache lock之类等)
10、%Non-Parse CPU非解析cpu比例,公式为 (DB CPU – Parse CPU)/DB CPU,
1-5 Top 10 Foreground Events by Total Wait Time
Top 10 Foreground Events by Total Wait Time
| Event | Waits | Total Wait Time (sec) | Wait Avg(ms) | % DB time | Wait Class |
|---|---|---|---|---|---|
| DB CPU | 3823.1 | 98.4 | |||
| log file sync | 10,933 | 101.5 | 9 | 2.6 | Commit |
| cursor: pin S | 3,299 | 23.4 | 7 | .6 | Concurrency |
| SQL*Net message to client | 7,835,076 | 13.3 | 0 | .3 | Network |
| latch: shared pool | 773 | 9.9 | 13 | .3 | Concurrency |
| direct path read | 29,439 | 4.2 | 0 | .1 | User I/O |
| library cache: mutex X | 681 | 3.1 | 5 | .1 | Concurrency |
| cursor: pin S wait on X | 73 | 2.6 | 36 | .1 | Concurrency |
| latch: row cache objects | 544 | 2.3 | 4 | .1 | Concurrency |
| SQL*Net more data to client | 122,900 | 2 | 0 | .1 | Network |
丰富的等待事件以足够的细节来描绘系统运行的性能瓶颈(Mysql梦寐以求的)
Waits : 该等待事件发生的次数
Times : 该等待事件消耗的总计时间,单位为秒,对于DB CPU而言是前台进程所消耗CPU时间片的总和
Avg Wait(ms) :该等待事件平均等待的时间,实际就是Times/Waits,单位ms,
Wait Class: 等待类型:
Concurrency,SystemI/O,UserI/O,Administrative,Other,Configuration,Scheduler,Cluster,Application,Idle,Network,Commit
常见的等待事件
=========================>
1、db file scattered read:
Avg wait time应当小于20ms如果数据库执行全表扫描或者是全索引扫描会执行 Multi block I/O ,此时等待物理I/O 结束会出现此等待事件。一般从应用程序(SQL),I/O 方面入手调整; 注意和index fast full scans (full) 以及 table scans结合起来一起看。
2、db file sequential read:
该等待事件Avg wait time平均单次等待时间应当小于20ms
db file sequential read单块读等待是一种最为常见的物理IO等待事件,这里的sequential指的是将数据块读入到相连的内存空间中,而不是指所读取的数据块是连续的。
3、latch free:
其实是未获得latch 而进入latch sleep
4、enq:XX 队列锁等待:
视乎不同的队列锁有不同的情况:
Oracle队列锁: Enqueue HW
enq: TX – row lock/index contention等待事件
enq: TT – contention等待事件
enq: JI – contention等待事件
enq: US – contention等待事件
enq: TM – contention等待事件
enq: RO fast object reuse等待事件
enq: HW – contention等待事件
5、free buffer waits:
是由于无法找到可用的buffer cache 空闲区域,需要等待DBWR 写入完成引起
一般是由于低效的sql、过小的buffer cache、DBWR 工作负荷过量引起,
6、buffer busy wait/ read by other session:
以上2个等待事件可以归为一起处理
7、write complete waits :
此类等待事件是由于DBWR 将脏数据写入数据文件,其他进程如果需要修改 buffer cache会引起此等待事件,一般是 I/O 性能问题或者是DBWR 工作负荷过量引起
")